クラスタを分析する
AIBooster POを導入したクラスタの状態について分析します。
Cluster Overview
Cluster Overview ダッシュボードはクラスタ全体の状態を一覧できるダッシュボードです。 このダッシュボードを定期的に確認することでクラスタ内で異常が生じたり、効率の悪いジョブが実行されている可能性を確認できます。
右上の時間範囲セレクタで観測期間を確認したい範囲に設定してください。
Cluster Overviewはダッシュボード一覧のAIBooster_POディレクトリ以下にあるCluster Overviewダッシュボードを選択することで開けます。
Cluster Overview: Job
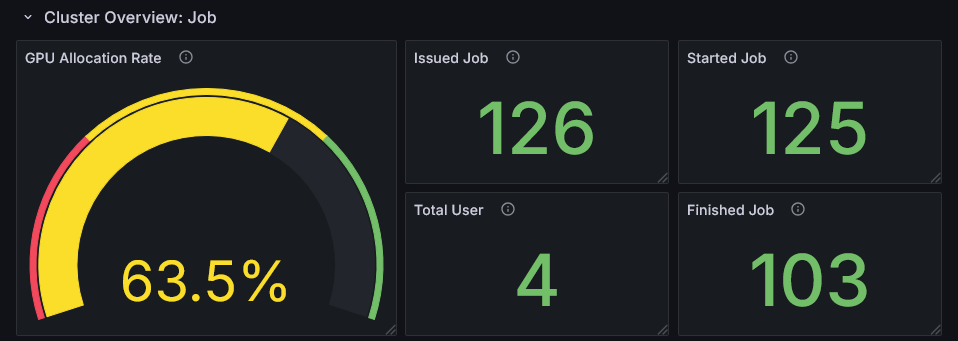
この行はクラスタ内のJobの稼働状況の統計情報を示します。
この行はクラスタ内にJob管理システムを導入していることを前提としたパネルで構成されています。
Job管理システムを導入していないクラスタ環境では正常な値を取得できません。
未対応の環境ではGPU Allocation Rate(画面左) が Unavailable 表記になります。
また、そのような未対応の環境では画面右の各指標は不正確な値が出力される可能性があります。
表示が不要な場合は、ヘッダ部分をクリックすることで折りたためます。
![]()
GPU Allocation Rate
この指標は全Jobが観測期間に対してどの程度の割合でGPUを確保していたかを表します。 この指標が低い場合、クラスタのユーザはあまりGPUを使用していないことを表します。 より積極的にGPUを活用するよう促したり、新しい作業の追加を検討することを推奨します。 一方で100%に近い場合、新しいJobを追加することが困難であるため、各Jobの性能改善を検討することを推奨します。次の行にあるGPUのハードウェアメトリクスを確認してください。
Issued Job, Started Job, Finished Job
観測期間中のJobの実行状況に関する統計情報です。
Issued Jobは期間中にユーザがJobを追加した数を表します。
Started JobはIssued JobとしてカウントされたJobのうち、期間中に実行を開始した数を表します。
Started JobがIssued Jobに比べて著しく低い値になっていた場合、Jobの実行待ちが発生しユーザの作業が滞っている可能性があります。
Finished JobはIssued JobとしてカウントされたJobのうち、期間中に開始し完了まで実行した数を表します。
Finished JobがIssued Jobに比べて著しく低い値になっていた場合、次のことが考えられます。
- クラスタ内で実行されているJobは観測対象期間よりも長いタイムスパンで実行されている傾向がある
- 観測対象期間の終了直前に大量のJobが発行されていた
Cluster Overview: Averaged Metrics
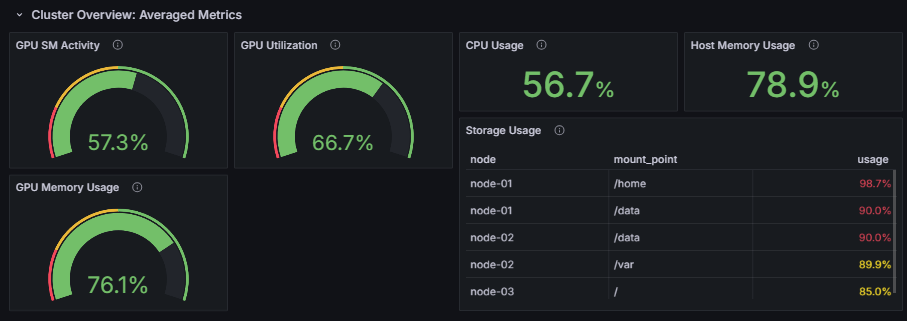
この行はクラスタ全体のハードウェアメトリクスを表示します。
GPU SM Activity, GPU Utilization, GPU Memory Usage
これらのメトリクスはクラスタ内にある全GPUの平均値を表示します。 それぞれの指標の意味は以下の通りです。
GPU SM Activity- GPUコアの実際の計算効率
- この値が高ければ、クラスタ内で実行されているGPU処理は高効率に実行されていることを示します
GPU Utilization- GPUを利用している期間の割合
- この値が100%であれば、クラスタ�内では常に何らかのGPUを使った処理が行われていることを示します
GPU Memory Usage- GPUメモリの使用割合
- 特にAIのワークロードではGPUメモリを多く使うような処理にすると効率的に動作する傾向があります
GPU Utilizationは「GPUで何らかのカーネルが実行されていた時間の割合」を示す指標です。
カーネルが1つでも動いていれば100%になるため、GPUの計算資源がどの程度使われているかまでは分かりません。
一方、GPU SM Activityは「GPUのStreaming Multiprocessor(SM)が実際に計算を行っていた時間の割合」を示します。
GPUの計算資源がどの程度活用されているかをより正確に反映します。
性能の改善方法は個別のJobごとに検討が必要ですが、概ね次のような対策方針が考えられます。
- ❌UtilizationもSM Activityも低い
- そもそもJobがGPUを使っているか確認する
- ⚠️Utilizationは高いが、SM Activityは低い
- GPUの処理をより効率的に動作できる処理に変更する
- ✅UtilizationもSM Activityも高い
- GPU処理に関しては効率的に動作しているので、別のアプローチを検討する
CPU Usage, Host Memory Usage
CPU Usageはクラスタ内に存在する全CPUコアの使用率平均を表します。
Host Memory Usageは全ノードのメモリ使用率の平均を表します。
CPUやメモリを大量に消費することが想定されるJobが稼働していないにもかかわらず、
これらの値が普段より高い値を示している場合、クラスタ上で何らかの異常が発生している可能性があります。
Storage Usage
Storage Usageでは、クラスタ上で使用率の高いストレージを確認できます。
ダッシュボード上部の「Mount Points」から監視対象のマウントポイントを選択します。
/home や /mnt のようなクラスタ運用上で監視したいマウントポイントを選択してください(複数選択可)。
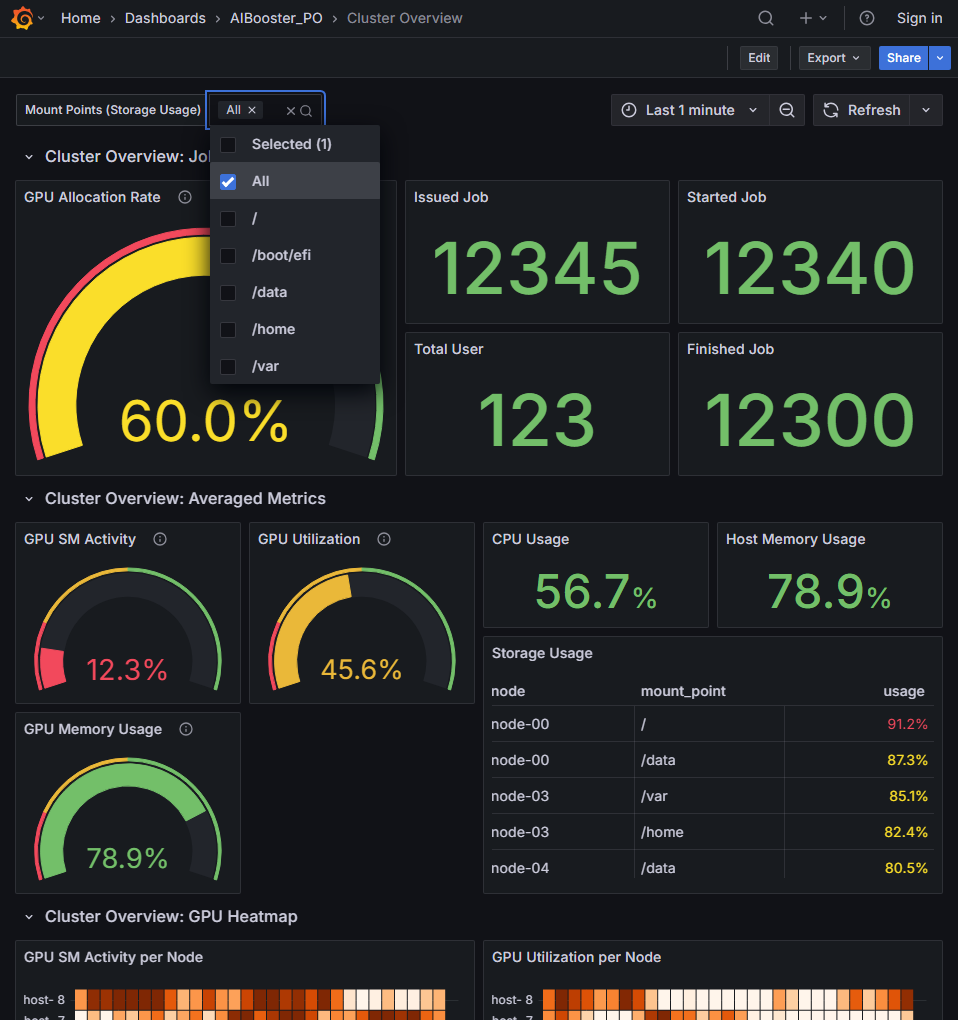
80%以上使用しているストレージ(マウントポイント)を最大5件表示します。 ストレージが枯渇する前に適切な対処を行うことでユーザの手を止めずに運用できるようになります。
- 共有ストレージを監視対象とした場合、複数のノードで同一の情報が表示されます
- 監視するマウントポイントパスの指定は全ノードで共通です
- 観測期間が過去の場合は観測期間最後の時点におけるストレージ状況を元に判定を行います
Cluster Overview: GPU Heatmap
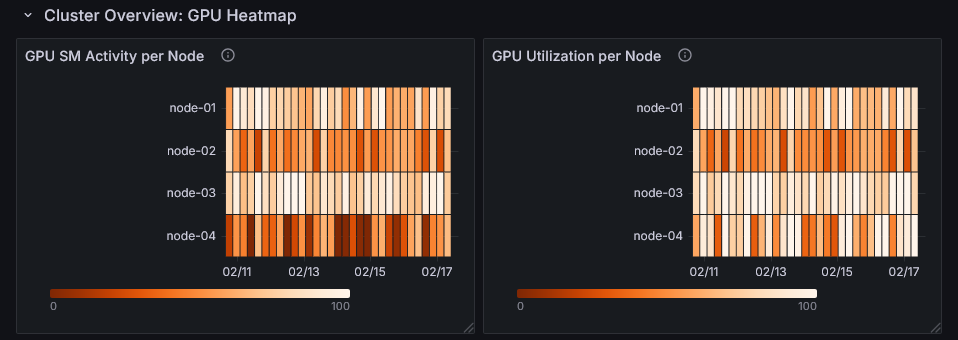
この行では、ノード単位のGPUの使用率(GPU SM ActivityおよびGPU Utilization)をヒートマッ�プとして表示します。
特定のノード、時間帯でGPUの使用率が高くなっているかを確認できます。
ヒートマップを参考にして特定のノードの稼働状況や同時刻帯で実行されたJobを調査することで性能改善の方針を考えられます。
Active Node List
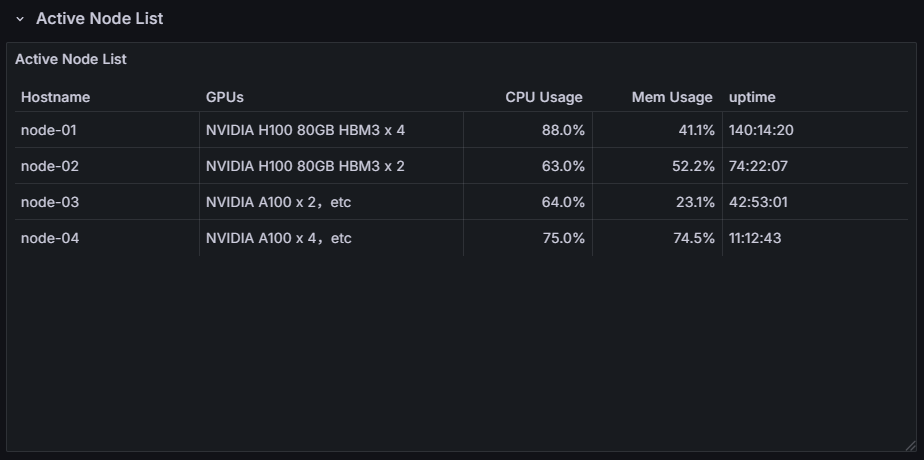
観測期間中に稼働していたノードの一覧を確認できます。 合わせて各ノードのCPU使用率、メモリ使用率、稼働時間 (観測期間最後の時点における稼働時間)を示しています。 ノード単位で意図しない状況が発生していないか確認できます。