AIBoosterとは?
AIBoosterは、AIワークロードの性能を継続的に観測し改善するためのパフォーマンスエンジニアリングプラットフォームです。
- PO: Performance Observability
- 🔍 可視化: 各種ハードウェアの使用率、効率などを一覧
- 📊 分析: ソフトウェアボトルネックを特定し、改善点を発見
- PI: Performance Intelligence
- ⚡ 性能向上: 自動チューニングで性能継続的に向上
- 💰 コスト削減: 非効率なリソース利用を削減しROIを改善
ユーザーは、可視化ダッシュボードを通じてCPU、GPU、インターコネクト、ストレージといった各種ハードウェアリソースの利用効率やソフトウェアのボトルネックを可視化し、AIワークロードの性能特性を分析することができます。 さらに、AIワークロード用にデザインされた最適化フレームワークを適用することで、効率的な性能改善が可能になります。
AIBoosterを活用して、高速かつ低コストなAIの学習や推論を始めましょう!
機能ハイライト
ZenithTuneによるハイパーパラメータチューニング体験の向上
大規模言語モデル(LLM)の分散学習では、テンソル並列・パイプライン並列・マイクロバッチサイズ・活性化再計算など、多数のパラメータが学習スループットに大きく影響します。しかしながら、これらのパラメータの最適な組み合わせはモデル構成やクラスタ環境に強く依存するため、手動での探索には専門知識と多大な試行錯誤が必要で�した。
AIBooster ZenithTune は、分散学習のハイパーパラメータを自動的に最適化し、学習スループットを向上させるためのフレームワークです。しかしながら、チューニングの定義にPythonスクリプトの記述が必要であり、これが導入のハードルとなっていました。また、最適化に非常に長い時間がかかるケースも存在していました。
本リリースでは、これらの問題を解決し、ZenithTuneによるハイパーパラメータチューニングの体験を向上させる大幅なアップデートを行いました。
ノーコードチューニング機能の追加
従来のZenithTuneでは、探索空間の定義・コマンド構築・出力パース・プルーニング条件を含む数十行のPythonスクリプトを記述する必要がありました。本リリースでは、Pythonスクリプトを一切記述せず、コマンドラインだけでハイパーパラメータチューニングを実行できるノーコードチューニング機能を追加しました。
フレームワークごとに用意されたプリセットを指定するだけで、パラメータ探索・コマンド実行・性能評価が自動的に実行されます。本リリースでは Megatron-LM および ms-swift に対応した megatron プリセットを提供しており、テンソル並列(TP)・パイプライン並列(PP)・コンテキスト並列(CP)・エキスパート並列(EP)などの並列化構成��、マイクロバッチサイズ、活性化再計算の設定を自動探索し、学習スループット(TFLOP/s/GPU)を最大化します。
zenithtune optimize --preset megatron \
--args n_gpus=8,gbs=64 \
--n-trials 50 --timeout-dynamic \
-- python pretrain_gpt.py --num-layers 30 --hidden-size 4096 --train-iters 3 ...
ノーコードチューニングの詳細については ノーコードチューニング を参照してください。
Megatron向けの新たな探索アルゴリズムの追加
従来のZenithTuneでは、Optunaベースの汎用的なBlackBox最適化のみを提供していました。本リリースでは、Megatronの並列化戦略に関するドメイン知識を活用した新たな探索アルゴリズムを2種類追加しました。
- ヒューリスティック探索(デフォルト): ドメイン知識に基づく決定的探索
- Staged BlackBox 探索: 段階的なベイズ最適化による探索
以下は、NVIDIA A100 x16GPU 上で Qwen3-Omni-30B の事後学習(SFT)を行う場合に対して、各探索戦略でハイパーパラメータチューニングを実行した比較結果です。
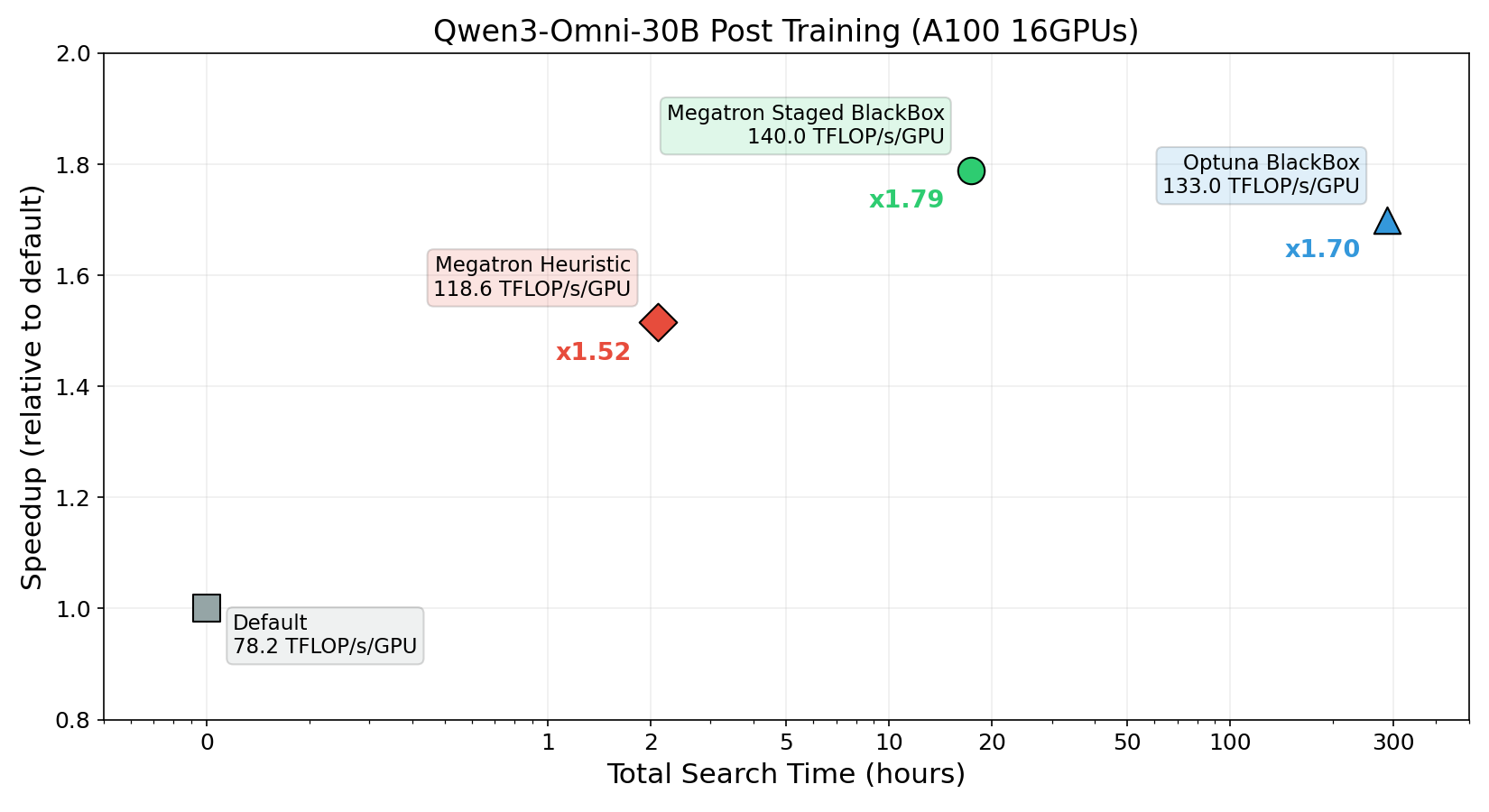
ヒューリスティック探索はわずか2時間程度の探索で学習スループットを 78.2 → 118.6 TFLOP/s/GPU に向上させ、1エポックあたりの学習時間を約1.52倍高速化しました。
Staged BlackBox 探索は約18時間の探索でスループットを 140.0 TFLOP/s/GPU まで引き上げ、約1.79倍の学習時間の高速化を実現しています。さらにこれは従来提供していたBlackBox最適化と比較して約1/16の探索時間で、より優れたハイパーパラメータが得られたことがわかりました。
これらの探索アルゴリズムをユースケースに応じて使い分けることで、ハイパーパラメータの探索時間と学習時間向上率のバランスを調整することができます。探索戦略の選び方を含む費用対効果の考え方については ハイパーパラメータチューニングの費用対効果 を参照してください。
✨ 各種ガイド
クイックスタートガイド
AIBoosterの概要、セットアップ方法と簡単な使い方について学びましょう。
性能観測ガイド
AIワークロードの性能を観測するための可視化ダッシュボードの使い方について学びましょう。
性能改善ガイド
AIワークロードの性能を改善するためのフレームワークの使い方について学びましょう。