ハイパーパラメータチューニングの費用対効果
ハイパーパラメータチューニングは学習期間を短縮する有力な手段ですが、チューニング自体もGPU時間とエンジニアリング工数を消費するため、費用対効果の判断が必要です。 本稿では、この判断を定量的に行う考え方を解説します。
1. はじめに
チューニング実施の判断基準
チューニングしない場合、デフォルト設定で学習を回すことになります。デフォルト設定はOOMを避けることを優先した保守的な構成であることが多く、ハードウェア性能を十分に引き出せていないケースも珍しくありません。
とはいえ、チューニングを実施するかどうかは、技術的に最適解を見つけられるかではなく、かけたコストを学習期間の短縮で回収できるかで決まります。
実際の現場では、たとえば次のような判断が求められます。
- 継続事前学習を3ヶ月回す予定だが、1週間かけてチューニングする価値はあるか?
- SFTを毎週実行しているが、チューニングスクリプトの開発に工数を割くべきか?
- ブラックボックス最適化を100試行すれば改善率は上がるが、10試行のヒューリスティックで十分ではないか?
本節では、こうした判断を感覚ではなく、学習期間・探索コスト・改善率・再利用回数の観点から定量的に整理します。
本文書での前提
対象は学習の実行時間性能を改善するチューニングです。並列化構成(Tensor Parallelism: TP、Pipeline Parallelism: PP、Expert Parallelism: EP等)、マイクロバッチサイズ、再計算戦略などを最適化し、スループットを向上させるケースを想定します。
モデル精度に影響するハイパーパラメータ(学習率、演算精度等)のチューニングは対象外です。
2. 損益分岐の基本的な考え方
チューニングすべきかどうかは「探索と実装にかかるコスト」と「高速化効果 × 再利用回数」の大小で判断できます。最も重要な変数は再利用回数 (同じ最適化設定を何回利用するか)です。 が大きいほどチューニングへの投資を回収しやすくなります。
基本の不等式
チューニングの採算が合うかどうかは、以下の不等式で判断できます。
左辺(コスト)より右辺(高速化効果)が大きければ採算が合います。実装コスト の場合はすべてGPU時間で判断でき、以降の議論では主にこのケースを扱います。
変数定義
| 変数 | 意味 | 単位 |
|---|---|---|
| チューニング前のジョブの学習期間 | 時間(h) | |
| GPU数 | 台 | |
| チューニング後に実測された改善率 | %(0〜100) | |
| チューニング前に見積もる期待改善率 | %(0〜100) | |
| 探索回数 | 回 | |
| チューニング1試行あたりの実行時間(ある構成で短い学習を走らせてスループットを計測する) | 時間(h) | |
| 最適化設定を利用する総回数 | 回 | |
| チューニングスクリプトの実装・検証工数 | 人時 |
3. コストの内訳
探索コスト
たとえば、8GPUで25分の試行を100回実行すると:
実装コスト の場合、探索コストと高速化効果が同じ 倍でスケールするため、GPU数は損益分岐式から消えます。ただし、実装コストを含む場合は大規模クラスタほど回収が速くなるなど、運用上の判断では無視できない場合もあります。
実装コスト
には以下が含まれます。
- チューニングスクリプトの開発
- テスト・検証
- 既存パイプラインへの組み込み
- ドキュメント作成
既存ライブラリ(ZenithTuneのプリセット機能等)を利用する場合は工数をほとんどかけずに済みますが、独自構築すると大きな工数が必要になるため、ライブラリの活用が 削減の鍵になります。人時を含める拡張は第5節で扱います。
待ちコスト(定性的)
探索コストはGPU時間として計上されますが、チューニング実行中にクラスタが占有され他のジョブが待たされるという間接的なコストは数式に含まれていません。特にクラスタの利用率が高い環境では、チューニングのスケジュール調整も判断材料になります。
4. メリットの定量化
1回あたりの高速化効果
チューニングにより改善率 % が得られた場合、1回の学習実行で得られる高速化効果は:
GPU時間に換算すると:
たとえば、720時間(30日)の学習ジョブが10%改善された場合、1回あたり72時間分の高速化効果です。 = 25/60 h(25分)の試行であれば、 回分の探索コストに相当します。
総高速化効果
同じ最適化設定を 回利用した場合の総高速化効果は:
は損益を左右する変数です。 では採算が合わなくても、 や は採算が合う場合があります。
アルゴリズム選択で注目すべき2つの軸
チューニングアルゴリズムを変えると、探索回数 と改善率 が変わります。この2つが損益分岐を決める主要な軸です。以下では3つのアルゴリズムを例に議論します。
- ヒューリスティック: 経験則に基づき少ない探索回数で構成を絞り込むアルゴリズム。ZenithTuneでサポート
- ブラックボックス最適化: ベイズ最適化等でスループットを目的関数として自動探索する手法。ZenithTuneではOptunaをベースにサポート
- 全探索: 探索空間のすべての組み合わせを試すグリッドサーチ
一般にこの順で が大きくなり、それに伴い も高くなる傾向がありますが、優秀なヒューリスティックは少ない で高い を達成することもあります。
- 初期コスト(探索コスト ): 探索回数 が増え��るほど、チューニングに必要なGPU時間が増える
- 1回あたりの高速化効果(): 改善率 が高いほど、学習を実行するたびに得られる時間短縮が大きくなる
アルゴリズムを選ぶ際は、 を増やすことで高くなる の値が、探索コストの増加に見合うかを確認します。損益分岐回数は以下で求められます。
以下の図は、 = 150h、 = 25分の条件で、3つのアルゴリズムの総高速化効果が再利用回数 に応じてどのように積み上がるかを示しています。実線の傾きが1回あたりの高速化効果、点線が各アルゴリズムの探索コスト、丸印が損益分岐点です。
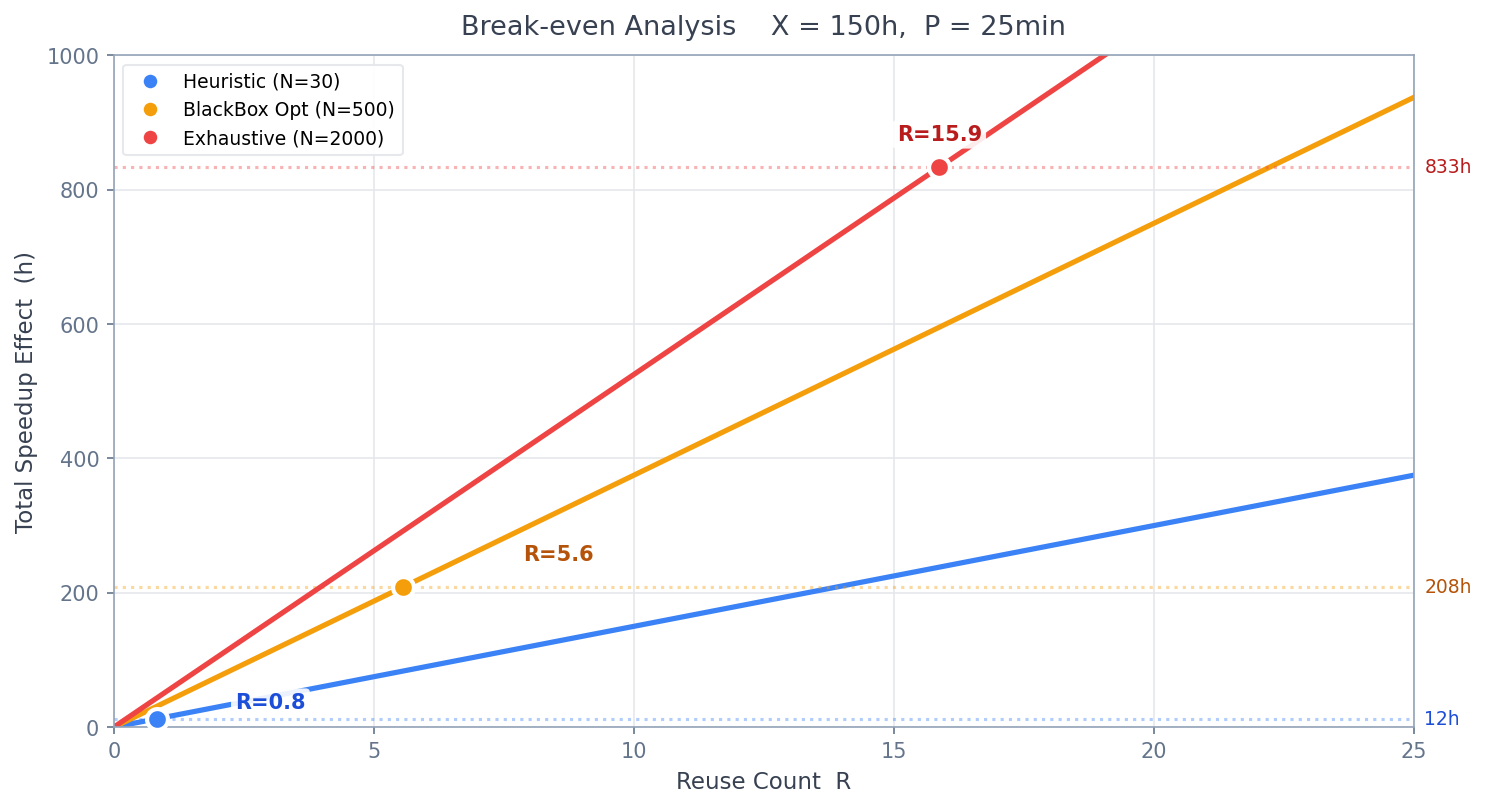
- ヒューリスティック(N=30, Z=10%): 探索コスト約13h、傾き15.0h/回 → で損益分岐
- ブラックボックス最適化(N=500, Z=25%): 探索コスト208h、傾き37.5h/回 → で損益分岐
- 全探索(N=2000, Z=35%): 探索コスト833h、傾き52.5h/回 → で損益分岐
ヒューリスティックからブラックボックス最適化に切り替えると、探索回数は約17倍に増えますが、傾き(1回あたりの高速化効果)は2.5倍にしかなりません。この追加コストに見合うかどうかは、 の大きさで決まります。
の見積もり
の値��はチューニング対象のアプリケーションの性質によって大きく異なるため、事前の見積もりが重要です。
- が小さいケース: 2-3回限りの事前学習、特定モデルの1回限りのファインチューニング
- が大きいケース: 定期的に繰り返すSFT・強化学習(推論精度に関するパラメータをグリッドサーチする場合等)
を大きくするには、特定のモデル・データセットに依存しないパラメータ(並列化構成等)を最適化対象にし、同じクラスタ構成・フレームワークの組み合わせで結果を再利用します。
5. 実装コストを含む場合の導出
GPU時間あたりのコストを 、エンジニア1人時あたりのコストを とすると:
について解くと:
- : 探索コストの回収に必要な再利用回数
- : 実装コストの回収に必要な再利用回数
の分母に があるため、大規模クラスタほど実装コストの回収が速くなります。
6. 継続事前学習と事後学習の違い
2つのフェーズの特性
| 継�続事前学習 | 事後学習(SFT・強化学習) | |
|---|---|---|
| 学習期間 | 大(数百〜数千時間) | 小(数時間〜数十時間) |
| 再利用回数 | 小(1〜数回) | 大(数十〜数百回) |
| 費用対効果の見通し | 明快(1回で大きな高速化) | 不明瞭(小さな高速化の積み上げ) |
| 主な判断軸 | が十分大きいか | が十分大きいか |
継続事前学習の場合
継続事前学習は が数百〜数千時間に及ぶため、少しの改善でも大きな高速化効果が得られます。
- = 2160h(90日)、 = 10% → 1回あたり216時間分の高速化
- 探索コストが100時間( = 100h)だとしても、 で回収可能
判断のポイント:
- が小さい(多くの場合1〜3回)ため、「この1回で回収できるか」が問い
- が大きいので、低コストなヒューリスティックでも十分な改善が期待できる
- 高コストなブラックボックス最適化を行う余裕もあるが、 が小さいため費用対効果はヒューリスティックと大差ない場合もある
事後学習(SFT・強化学習)の場合
事後学習は が小さい(数時間〜数十時間)代わりに繰り返し頻度が高いため、 の見積もりが判断の鍵になります。
- = 10h、 = 10% → 1回あたり1時間分の高速化
- なら探索コスト12.5時間(ヒューリスティック: = 30, = 25分)でも回収できない
- しかし なら累計50時間分�の高速化で回収可能
1回あたりの高速化効果は小さくても、 が大きければ累積で回収できます。
判断のポイント:
- 今後どれだけ同じ構成で学習を繰り返すかを見積もる
- 低コストなアルゴリズム(ヒューリスティック)が特に有利(探索コストが小さいので少ない で回収可能)
- 高コストなアルゴリズムは がかなり大きくないと回収できない
メモリ余裕の確保
事後学習では精度に関するパラメータのグリッドサーチやマルチノードでの実行など、メモリ消費が変動しやすい状況があるため、チューニングでメモリ効率の良い並列化構成を見つけておくとOOMのリスクを抑えることができます。
7. 判断の手順
ステップ1: 変数を見積もる
| 確認項目 | 問い |
|---|---|
| (学習期間) | このジョブは何時間走るか? |
| (再利用回数) | この最適化設定を�何回利用するか? |
| (探索コスト) | 候補のアルゴリズムでどれだけGPU時間を使うか? |
| (期待改善率) | 過去の実績や類似ケースから何%の改善が見込めるか? |
ステップ2: 損益分岐となる改善率を求める
損益分岐点の式から、採算が合うために必要な最低改善率 を求めます。
この値は「最低でもこれだけ改善しなければ採算が合わない」という基準です。
ステップ3: アルゴリズムごとに と を比較して判断する
アルゴリズムごとに が異なるため、 も変わります。各アルゴリズムについて と を比較し、採算が合うアルゴリズムの中からコストと効果のバランスで選択します。
Z_e が Z_break を大きく上回る → そのアルゴリズムでチューニングを実施
Z_e が Z_break とほぼ同等 → より低コストなアルゴリズムに切り替えて再検討
Z_e が Z_break を下回る → そのアルゴリズムでは採算が合わない
迷ったときは、最も低コストなアルゴリズム(ヒューリスティックや、探索回数を抑えたブラックボックス最適化)から始めるのが安全です。
- 探索コストが小さいため、損失リスクが低い
- 得られた改善率 を実測値として、より高コストなアルゴリズムへの投資判断に使える
の見積もりにはGPUプロファイリングの知見が必要です。AIBoosterのPerformance Observability(PO)を活用すると、GPU利用率やSMコアの利用率などを可視化でき、プロファイリングを取らなくても簡易的にを見積もることが可能です。また、 の見積もりにはプロジェクト計画全体を見通す必要があります。GPUワークロードの最適化に精通した専門家やコンサルタントに相談するのも選択肢のひとつです。
8. まとめ
基本の不等式の , , , の4変数を見積もって判断します。 チューニングの問い��は「やるかやらないか」ではなく「どのアルゴリズムを、どの程度のコストで実施するか」です。ZenithTuneではこの問いに答えるべく、コストと高速化効果に応じた複数のアルゴリズムを提供しています。自分のユースケースに最適なコストと高速化効果のバランスを取れるアルゴリズムを選択しましょう。