Visualizing GPU Details Profile Results
You can check the following information on the details profile summary screen. For details on how to use details profiling, see Performance Details / Profiling [Beta].
Analysis - Overview
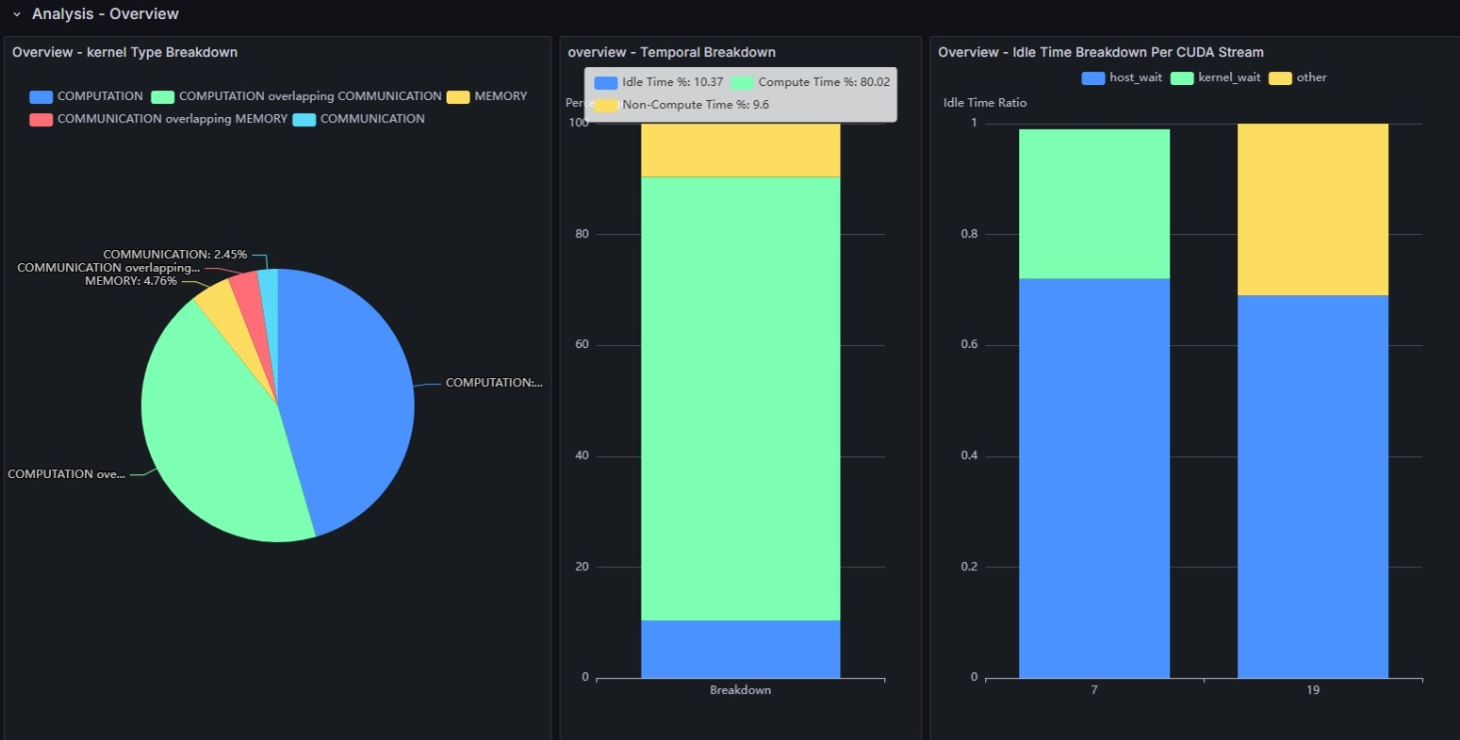
Overview - Kernel Type Breakdown
This shows the execution time breakdown of kernels running on the GPU, categorized into the following three types:
- COMPUTATION
- COMMUNICATION
- MEMORY
GPUs can execute each type in parallel. Items marked with "overlapping" indicate that multiple types of kernels are executing simultaneously. In most cases, parallel execution is desirable as it enables better hardware utilization.
Overview - Temporal Breakdown
This shows the breakdown of GPU execution status into three categories and their respective proportions:
- Idle Time
- Compute Time
- Non-Compute Time
Idle Time represents periods when nothing is executing on the GPU. Non-Compute Time represents periods when computation is not being performed, but data transfers, memory copies, or collective communications are taking place.
Idle Time Breakdown Per CUDA Stream
CUDA processes multiple operations in parallel by grouping them into units called CUDA Streams. However, depending on the dependencies, subsequent operations may need to wait for the completion of preceding operations.
host_wait represents situations where the current kernel execution starts after the end time of the previous kernel, meaning there are no executable operations available on the GPU side.
kernel_wait is recorded when a short idle time occurs between two kernel executions.
This idle time is thought to be caused by the overhead of kernel launching.
Analysis - Computation
Computation - Summary
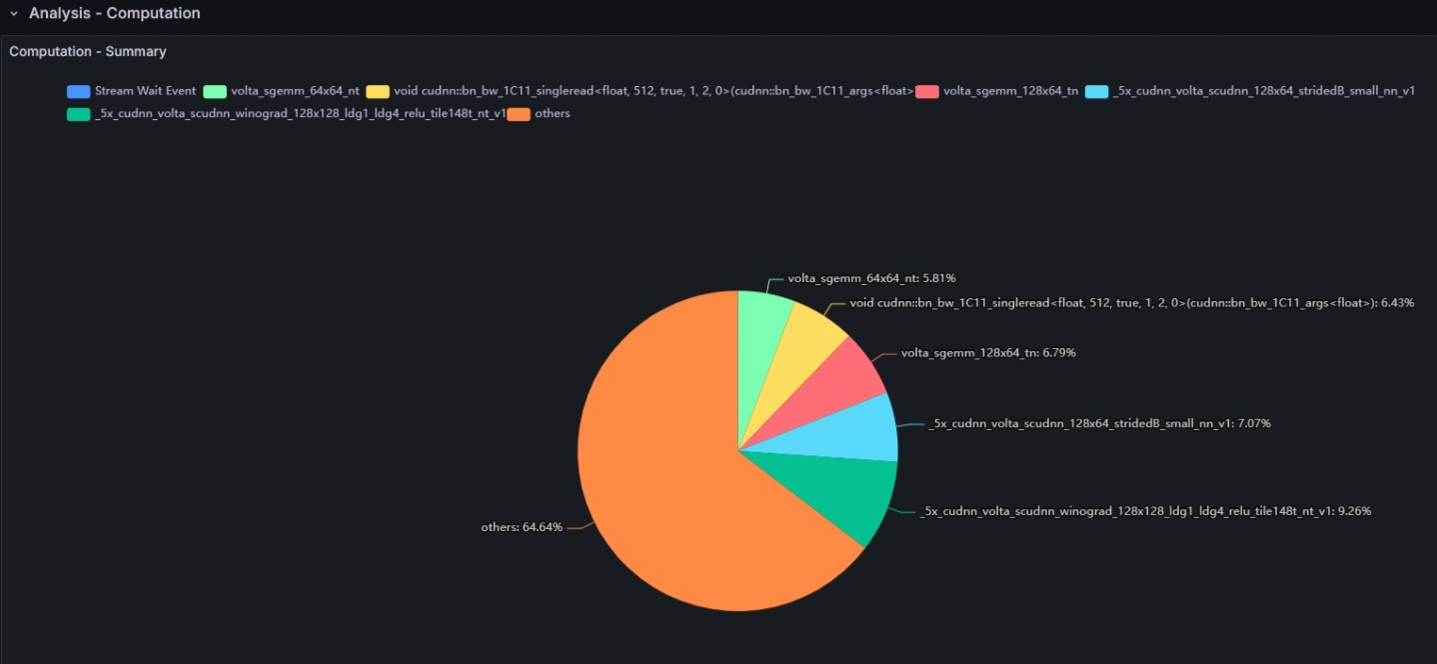
This graph shows the kernel functions that occupy the top positions in the execution time breakdown among all kernel operations executed on the GPU.
Analysis - Memory
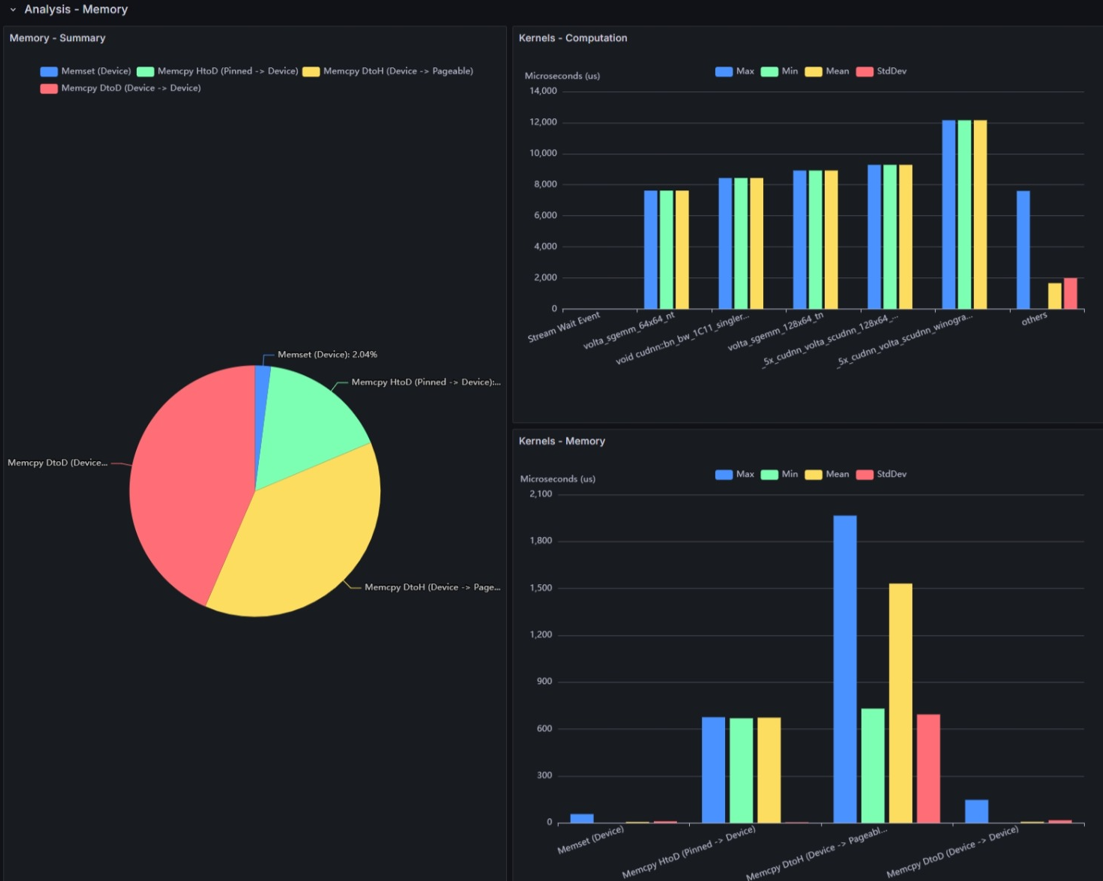
Memory - Summary
This shows the breakdown of GPU memory operations (memset/memcpy) by type and transfer direction:
- Memset (Device)
- Memcpy DtoD
- Memcpy HtoD
- Memcpy DtoH
Generally, data transfers between Host and GPU Device such as HtoD and DtoH are considered slow, so fewer occurrences are preferable.
Kernels - Computation
This shows execution time statistics for kernel functions that occupy the top positions in the execution time breakdown.
Kernels - Memory
This shows execution time statistics for GPU memory operation processes.
Analysis - Communication
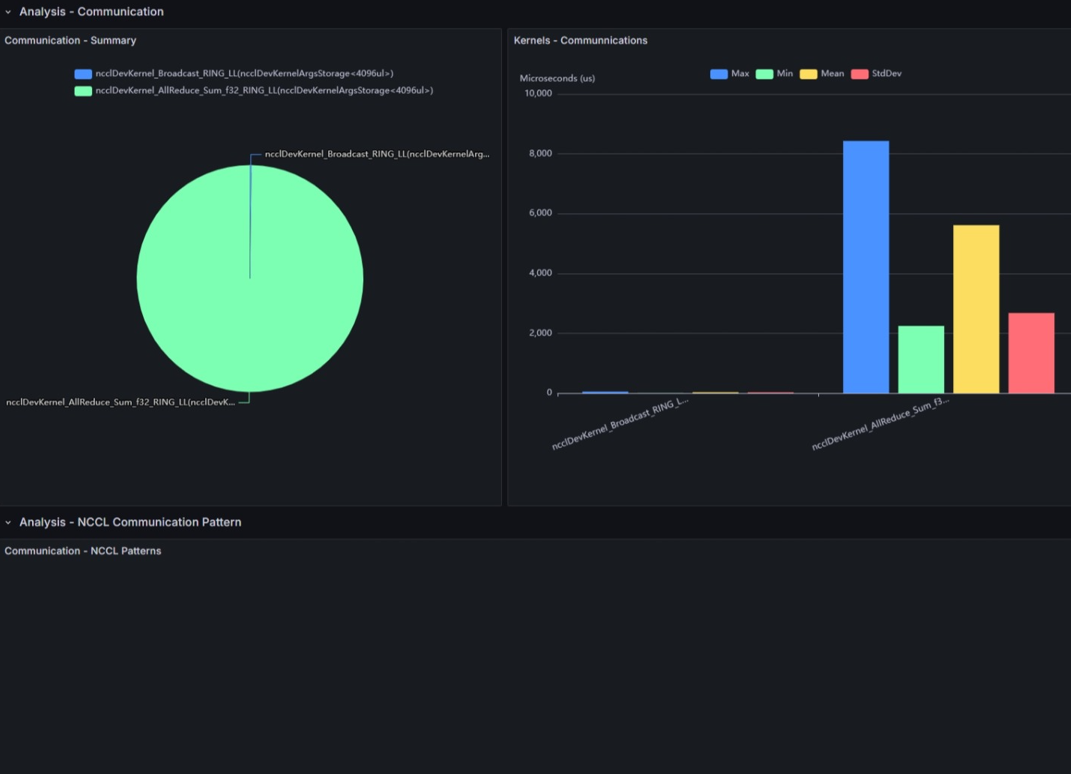
Communication - Summary
For communication between GPUs, many environments internally use NCCL (NVIDIA Collective Communications Library).
This shows the execution time breakdown for each NCCL communication operation used.
Kernels - Communications
This shows execution time statistics for each NCCL kernel operation used.
Analysis - NCCL Communication Pattern
Currently, this can only be obtained in some environments.