GPU詳細プロファイル結果の可視化
詳細プロファイルの要約情報画面では以下の情報を確認することができます。 詳細プロファイルの使用方法に関しては Performance Details / Profiling [Beta] を確認してください。
Analysis - Overview
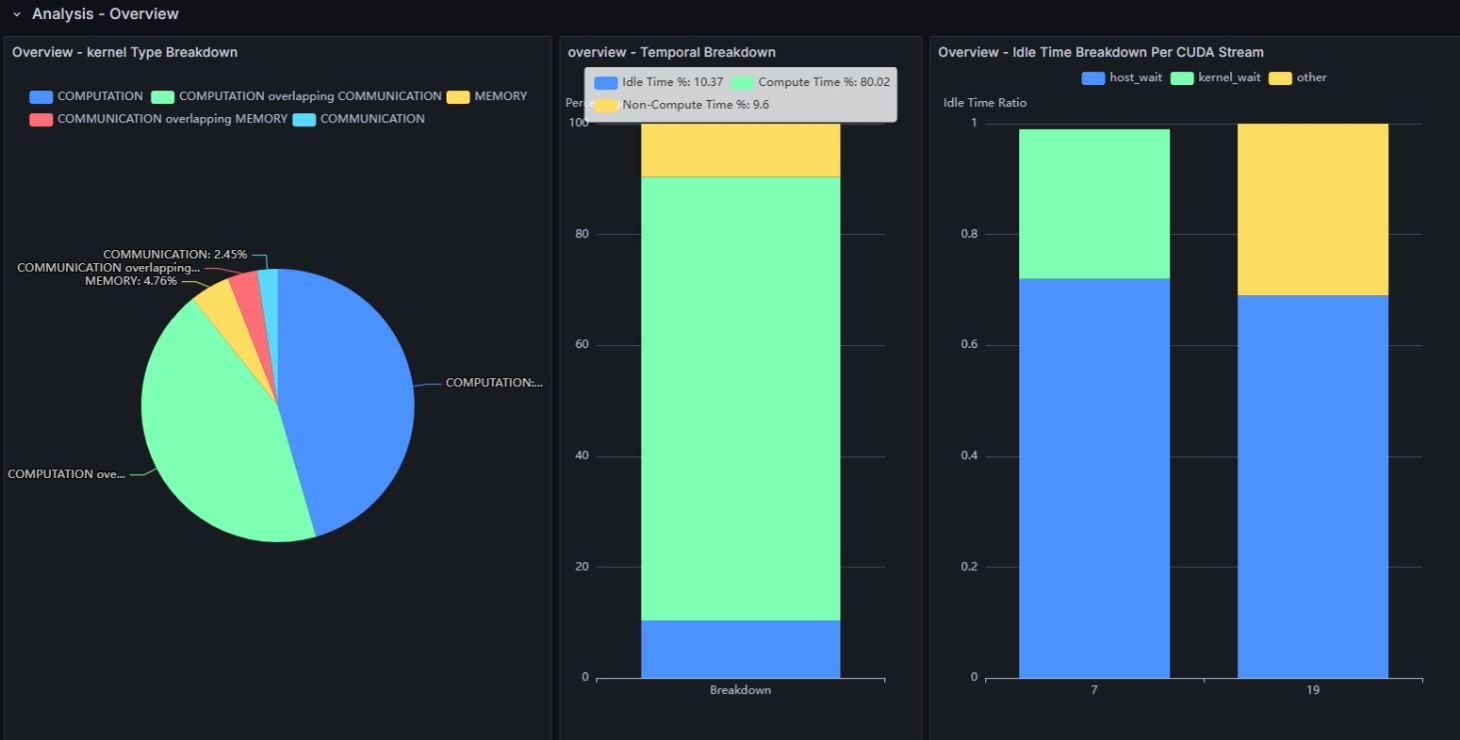
Overview - Kernel Type Breakdown
GPU上で実行されているカーネルを以下の3つの種類に分け実行時間の割合を示します。
- COMPUTATION
- COMMUNICATION
- MEMORY
GPU上では各種類を並列に実行可能です。 overlapping 付きの項目は複数種のカーネルが同時に実行されていることを示します。 多くのケースでは並列に実行されているとHWを活用できており望ましいと考えられます。
Overview - Temporal Breakdown
GPUの実行状況を3つの状況に分けて、その割合を示します。
- Idle Time
- Compute Time
- Non-Compute Time
Idle TimeはGPU上で何も実行されていない時間、 Non-Compute Timeは計算処理を行っていないが、データ転送やメモリコピー、集団通信が行われている時間を示します。
Idle Time Breakdown Per CUDA Stream
CUDAではCUDA Streamという単位で複数の処理がまとめられて並行に実行されますが 依存関係によっては前段の処理が完了するまで後段の処理を待機する必要が生じます。 このグラフでは待機時間が何の要因で発生しているかCUDA Streamごとの割合を示します。
host_waitは現在のカーネルの実行が前のカーネルの終了時刻より後に開始されているため、GPU側で実行可能な処理が無い状況を表します。
一方、kernel_waitは、2つのカーネル実行の間に短いアイドル時間が発生した場合に記録されます。 これは、カーネル起動のオーバーヘッドが原因で発生するアイドル時間と考えられます。
Analysis - Computation
Computation - Summary
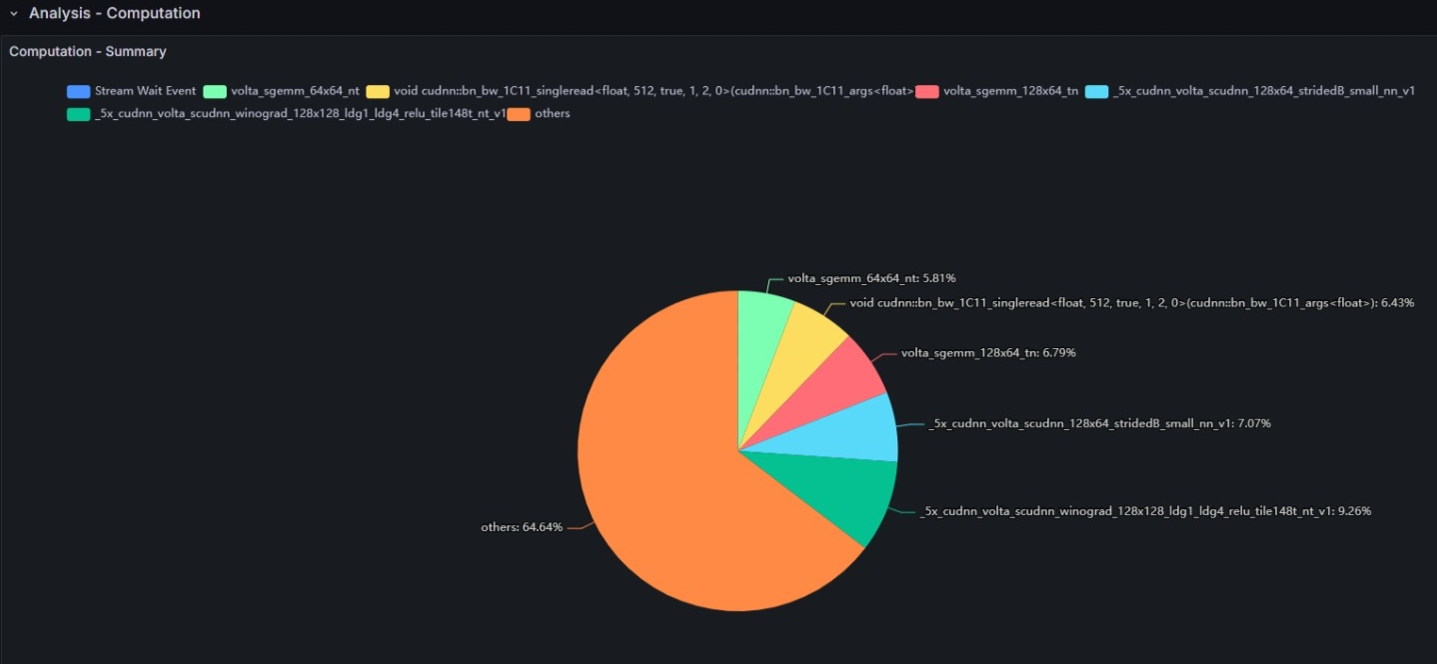
GPUで実行される全てのカーネル処理のうち、処理時間の内訳で上位を占めるカーネル関数を示したグラフです。
Analysis - Memory
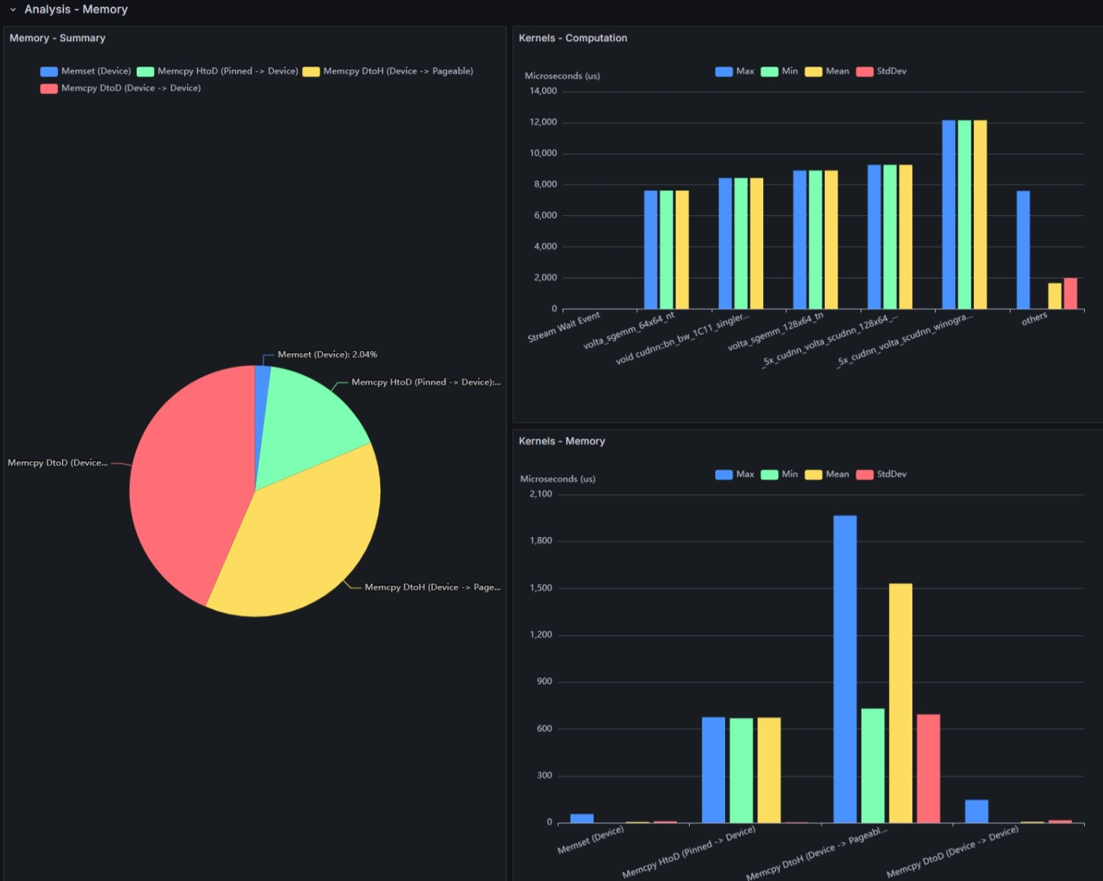
Memory - Summary
GPU上のメモリ操作(memset/memcpy)の実行の種類や転送方向別での内訳を示したものです。
- Memset (Device)
- Memcpy DtoD
- Memcpy HtoD
- Memcpy DtoH
一般にHtoDやDtoHのようなHostとGPU Device間でのデータ転送は低速と考えられるため、少ない方が望ましいと考えられます。
Kernels - Computation
処理時間の内訳で上位を占めるカーネル関数の実行時間の統計を示しています。
Kernels - Memory
GPU上のメモリ操作処理の実行時間の統計を示しています。
Analysis - Communication
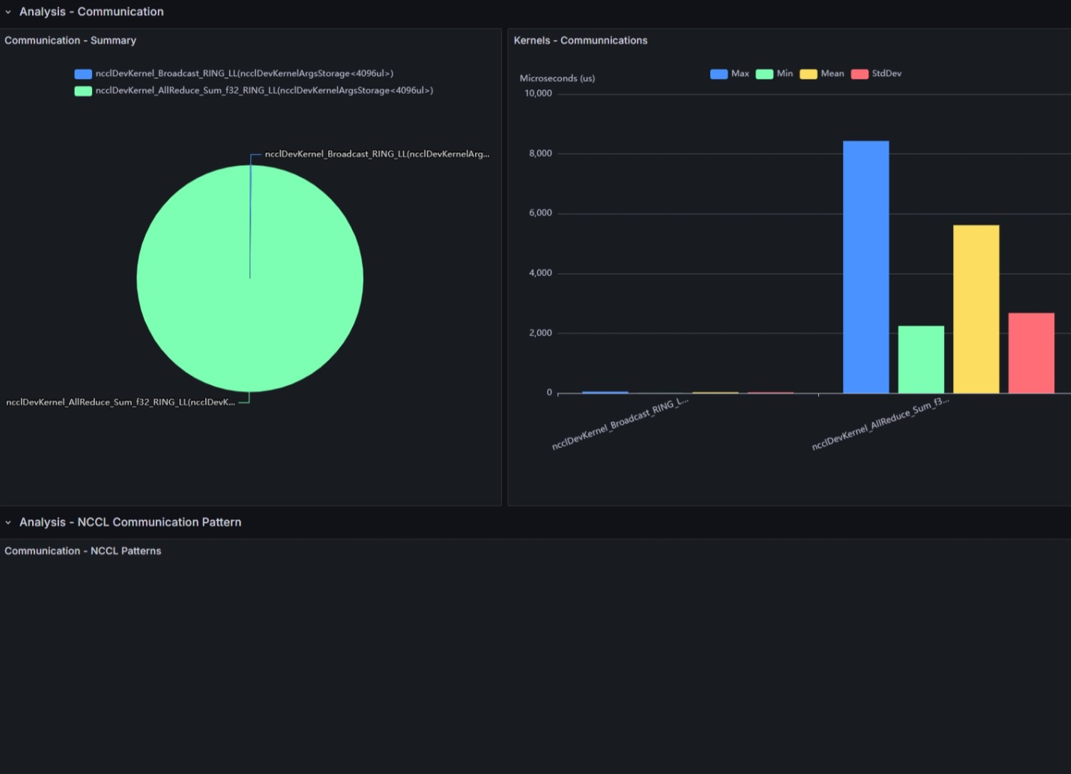
Communication - Summary
GPU間で通信を行うために、多くの環境では NCCL(NVIDIA Collective Communications Library) が内部的に使用されています。
使用されたNCCLの通信処理ごとに実行時間の内訳を示したものです。
Kernels - Communications
使用されたNCCLのカーネル処理ごとに実行時間の統計を示しています。
Analysis - NCCL Communication Pattern
現在、一部の環境でのみ取得ができます。