ケーススタディ
AIBooster上で各種メトリクスを観測・分析し、どのように性能向上に繋げるのかをLlama4 Scoutの継続事前学習の事例を用いて解説します。
環境と設定
学習環境
- 高火力PHY Sec.A x 4ノード
- GPU: NVIDIA H100 80GB x 8
- Interconnect: 200Gbps x 4
- Ubuntu 22.04 LTS
- AIBoosterによる初期セットアップ済み
- 性能観測ダッシュボード/プロファイリングツール
- 性能改善フレームワーク
- 推奨インフラ設定を適用
- モデル開発キット
学習設定・前提
- 学習ライブラリ:LLaMA-Factory
- データセット:RedPajama-V1 ArXiv Subset (28B Token Count)
- 公式サンプル(Llama3 フルパラメーターSFT)の設定値を流用して、モデル等だけを変更
- コード・モデル・データを配置した上で、各ノードで以下コマンドを実行
FORCE_TORCHRUN=1 \
NNODES=4 \
NODE_RANK=<0..3のノード番号> \
MASTER_ADDR=<ノード0のアドレス> \
MASTER_PORT=29500 \
llamafactory-cli train examples/train_full/llama4_full_pt.yaml
- 約28時間で3エポックの学習が完了
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 100892.0068, 'train_samples_per_second': 1.199, 'train_steps_per_second': 0.019, 'train_loss': 1.72523823162866, 'epoch': 3.0}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1890/1890 [28:01:32<00:00, 53.38s/it]
[INFO|trainer.py:3984] 2025-04-28 08:27:36,306 >> Saving model checkpoint to saves/llama4-109b/full/pt
..snip..
[INFO|tokenization_utils_base.py:2519] 2025-04-28 08:32:00,528 >> Special tokens file saved in saves/llama4-109b/full/pt/special_tokens_map.json
***** train metrics *****
epoch = 2.996
total_flos = 1557481GF
train_loss = 1.7252
train_runtime = 1 day, 4:01:32.00
train_samples_per_second = 1.199
train_steps_per_second = 0.019
Figure saved at: saves/llama4-109b/full/pt/training_loss.png
[WARNING|2025-04-28 08:32:00] llamafactory.extras.ploting:148 >> No metric eval_loss to plot.
[INFO|modelcard.py:450] 2025-04-28 08:32:00,937 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
収集したメトリクスの分析
AIBooster性能観測ダッシュボードで時系列メトリクスを観察した結果:
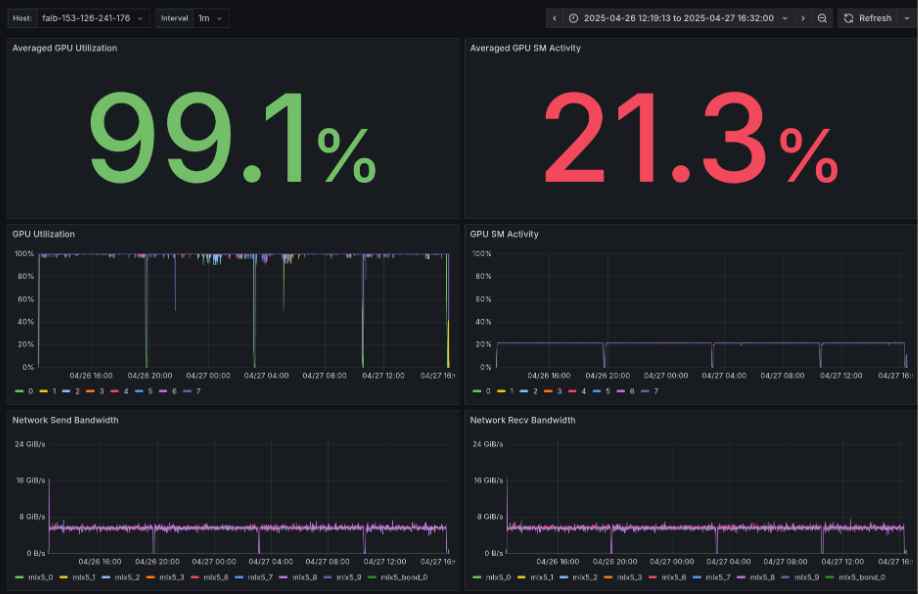
- Average GPU Utilization: 99.1%(一見して高い)
- Average GPU SM Activity: 21.3%(GPUコアの利用効率は20%台と低く横ばい)
- GPU Utilization, GPU SM Activity: 一定の間隔でGPUがストール
- Network Send/Recv Bandwidth: インターコネクト使用帯域はSend/Recvともに平均6GB/s程度(理論帯域は25GB/s)
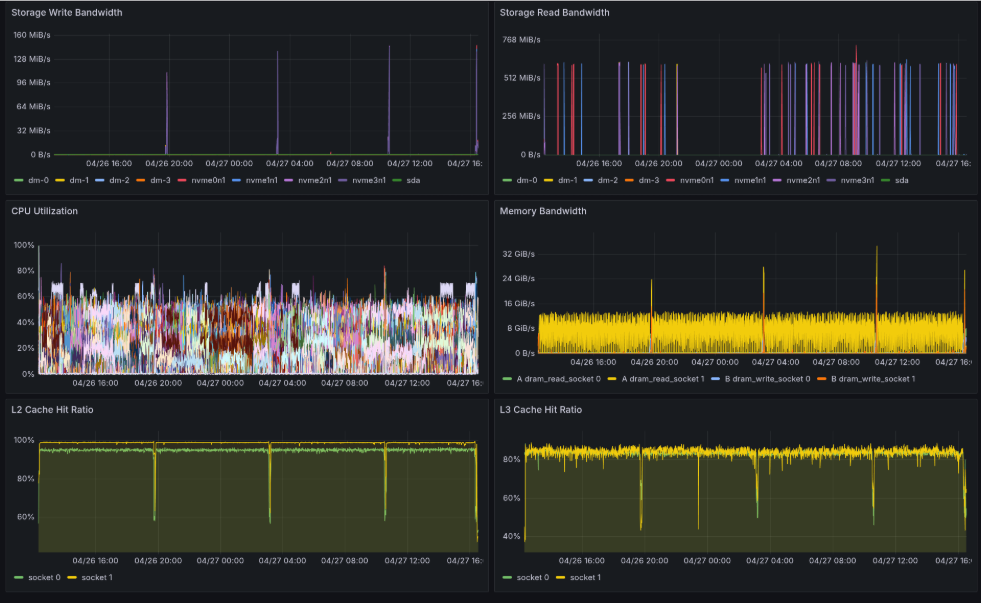
- Storage Write Bandwidth: GPUのストールに同調してStorage Writeが発生
- Storage Read Bandwidth: 断続的にStorage Readが発生
- CPU Utilization: CPUには余裕あり
フレームグラフ分析
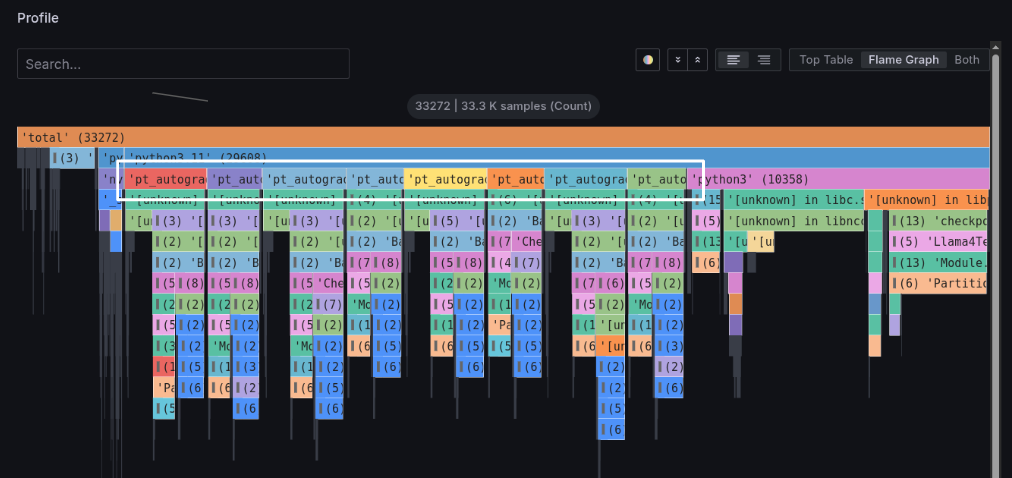
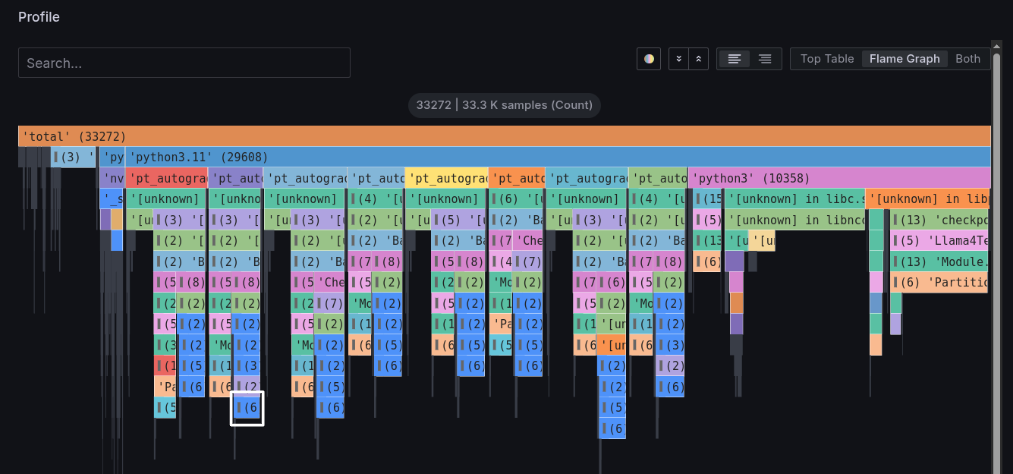
プロファイルパネルにおいて、Flame Graphボタンをクリックすると、拡大されたフレームグラフが閲覧できます。
上から3段目のpt_autograd_#Nという処理に注目してください。このPyTorchのEngineスレッドが、処理時間の大半を占めています。
また、各pt_autograd_#Nの下段に注目すると、処理が2つに分かれています。
まずは左側の処理について確認します。
下図の白線で囲った処理を左クリックして出てくるタブの中の、Focus Blockをクリックし、詳細を確認します。
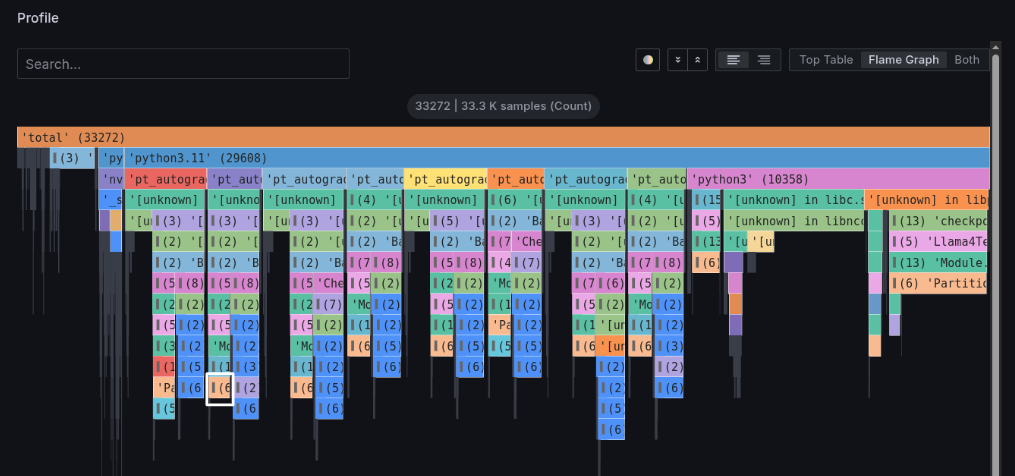
下図を見ると、DeepSpeedのfetch_sub_moduleという関数内でブロックされています。 このコードから、各ノードに分散配置されているパラメータの到着を待っているのでは?という予測ができます。
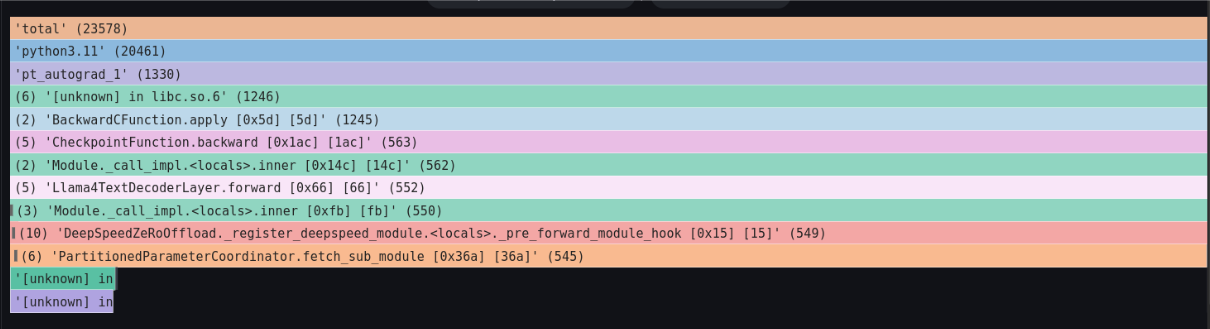
続いてpt_autograd_#Nの下の段の右側の処理について確認します。
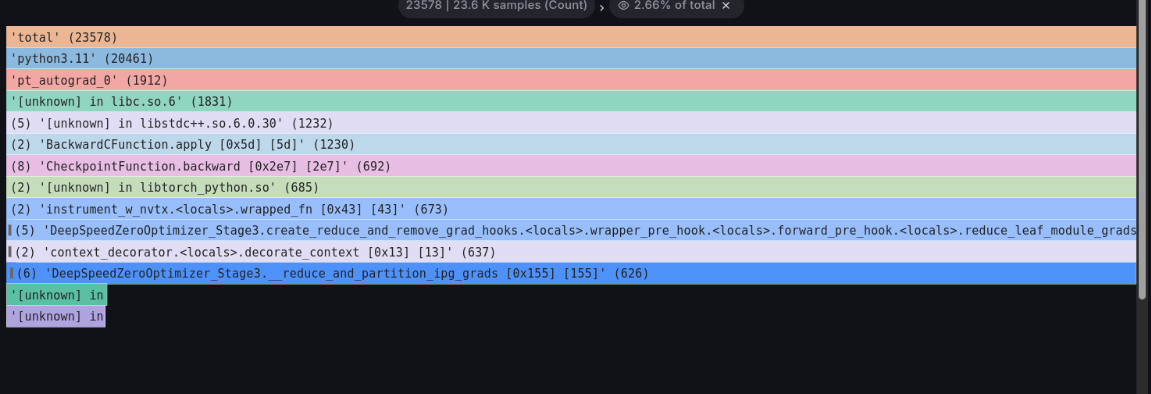
下図の白線で囲った処理を左クリックして出てくるFocus Blockをクリックし、詳細を確認します。
DeepSpeed ZeRo3の_reduce_and_partition_ipg_gradsという関数内でブロックされています。 このコードから、モデルの勾配の集約の完了を待っているのでは?という予測ができます。
分析のまとめ
上記のメトリクスとフレームグラフの分析から、以下のことが分かりました。
- GPUのフルパワーを出し切れていない
- チェックポイント書き出しと思われるGPUストールがあるが、全体からすると影響はごくわずか
- フレームグラフとコードの情報を総合すると、ノードに分散したデータの集約でブロックしている可能性がある
- 一方でインターコネクトの帯域には余裕あり
これらの観測結果から、分散学習における通信効率がボトルネックとなっているという仮説を立てることができます。具体的には、DeepSpeed ZeRO3のパラメータ分散・集約処理において、通信待機時間が演算時間を上回っていると推測されます。
改善施策:DeepSpeedのハイパーパラメータを最適化する
AIBoosterにはDeepSpeedの様々な性能パラメータを自動調整するためのツールが備わっています。
実行時間を最小化するようにDeepSpeed ZeRO3のコンフィグレーションパラメータセットの最適値を探索します。
詳しい使い方については性能改善ガイドをご覧ください。
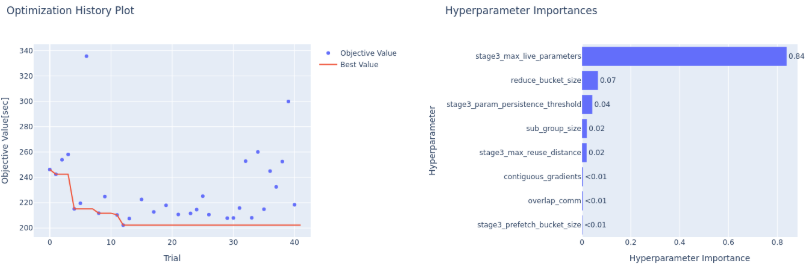
最適化結果
パラメータ変更:
| パラメータ名 | 最適化前 | 最適化後 |
|---|---|---|
| overlap_comm | false | false |
| contiguous_gradients | true | false |
| sub_group_size | 1,000,000,000 | 14,714,186 |
| reduce_bucket_size | 26,214,400 | 1 |
| stage3_prefetch_bucket_size | 23,592,960 | 473,451 |
| stage3_param_persistence_threshold | 51,200 | 4,304,746 |
| stage3_max_live_parameters | 1,000,000,000 | 6,914,199,685 |
| stage3_max_reuse_distance | 1,000,000,000 | 3,283,215,516 |
性能改善結果:
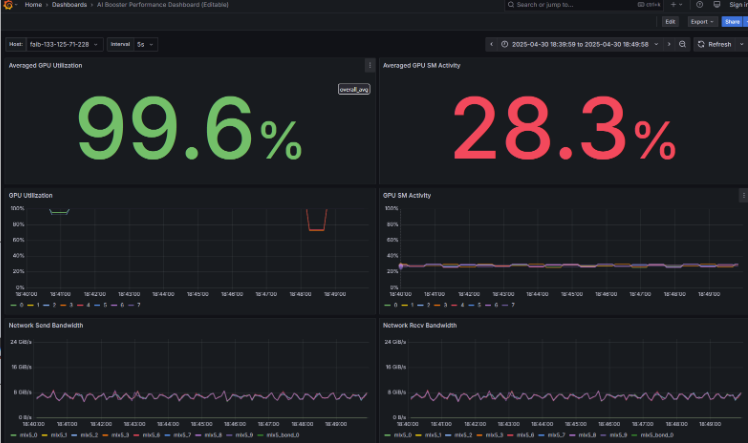
- 処理時間: 50[s/itr] → 40[s/itr](約20%改善)
- 通信帯域: 6.0 → 7.5[GiB/s](約25%改善)
- Average GPU SM Activity: 21% → 28%(約7%改善)
- 損失曲線に劣化は見られない
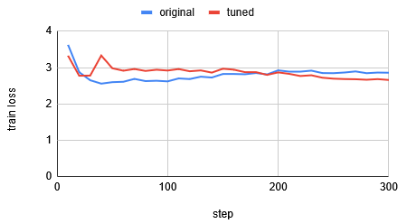
約40回の試行で得られた最適パラメータにより、学習性能が大幅に向上しました。
おわりに
ダッシュボードのメトリクスとフレームグラフを分析することで、何についてハイパラチューニングをしたらよいか、あたりを付けることができます(観測)。 その後PIを用い、パラメータセットの最適値を探索することで、性能改善を行うことができます(改善)。 パフォーマンスエンジニアリングでは、上記のような観測と改善のループが大切になります。
何がボトルネックかは環境・アプリケーションごとに異なります。 まずはダッシュボードで簡単に性能を観測してみましょう。