性能を分析する
Performance Overview
このダッシュボードでは、観測対象のすべてのGPUホストの性能に関する情報を一覧することができます。
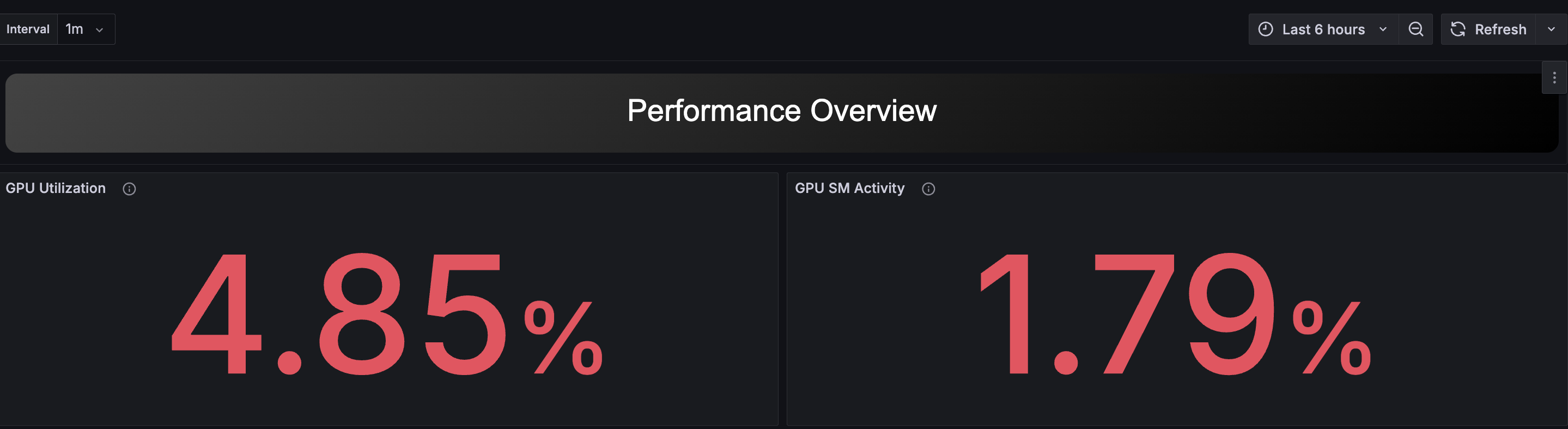
ページ最上部には、対象区間におけるGPUの重要なメトリクスの統計値が表示されています。 これらの値が100%に近いほど、GPUが頻繁に使用されていることを意味します。
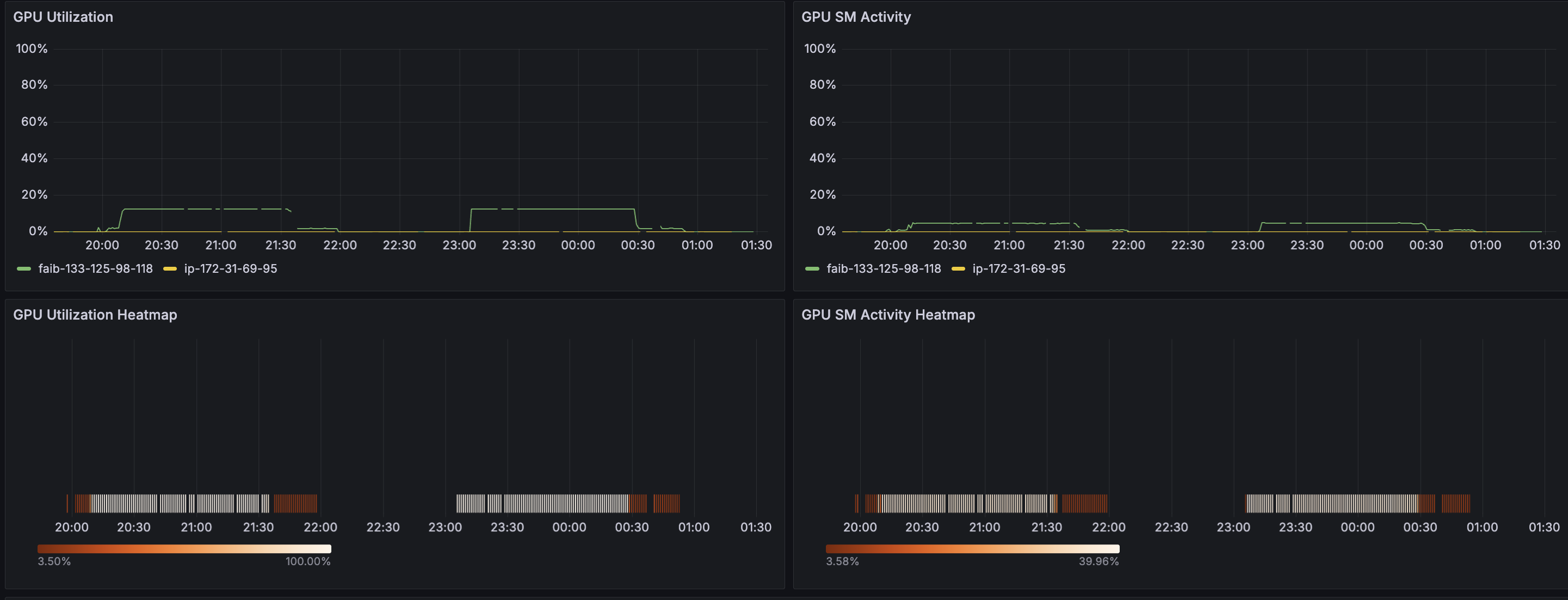
その下には、これらのメトリクスのホストごとの時系列推移や、GPUごとのヒートマップが合わせて表示されています。
ダッシュボードの最下部では、ホストやジョブの情報がテーブルとして表示されています。 各行はハイパーリンクになっており、このリンクをクリックすることで、該当するホストやジョブごとのPerformance Detailsダッシュボードに遷移することができます。
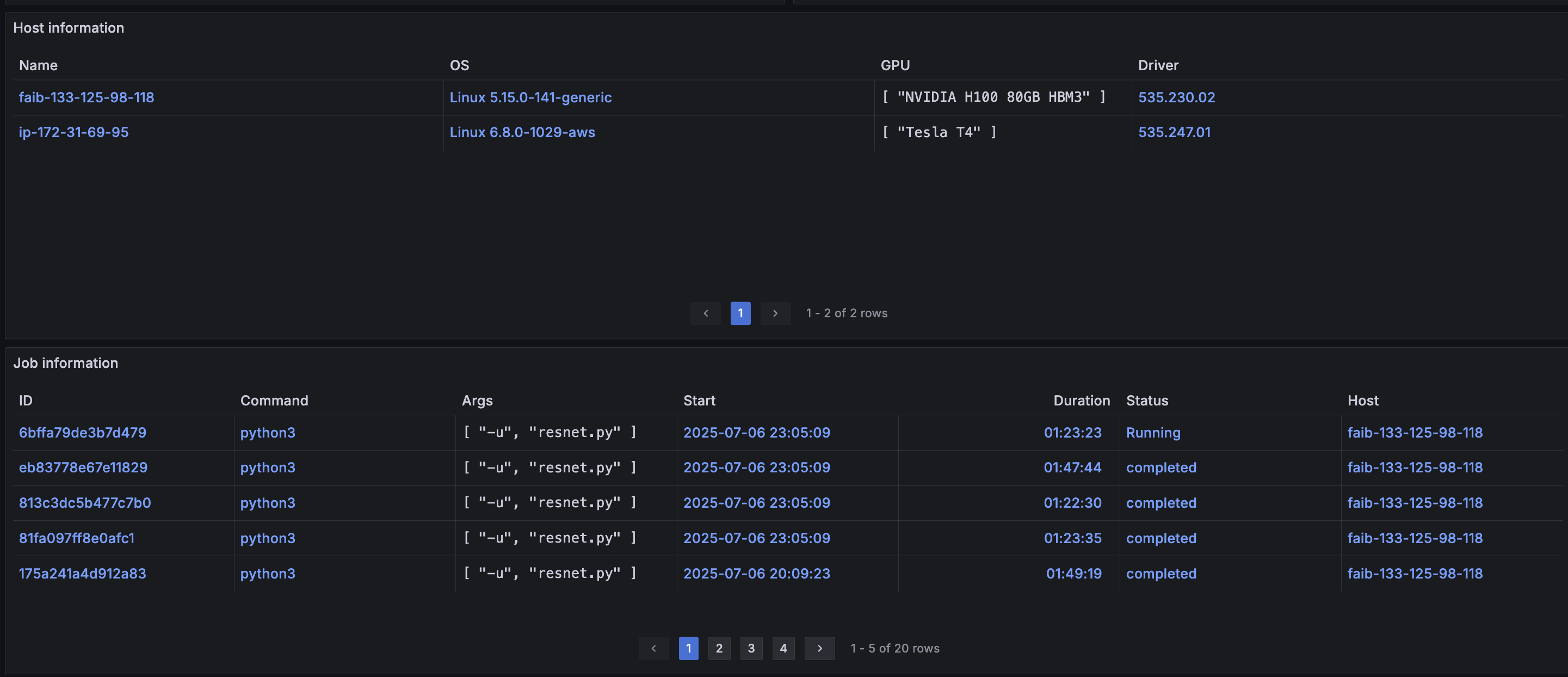
ホストとは、AIBoosterが観測している各計算機ノードのことです。
ジョブとは、プロセスツリーIDと呼ばれるプロセスに関するメタ情報が、特定の条件に当てはまるプロセスを指します。
プロセスツリーIDとは、あるプロセスのすべての親プロセスにおける /proc/<pid>/comm を古い順に並べ、 / で区切ったものです。
デフォルトでは、以下の正規表現にマッチするプロセスツリーIDがジョブとして扱われます。
systemd.*/([a-z]*sh|containerd-shim-runc-v2)/.*python[0-9.]*$
この表現を解釈すると、コンテナ内、あるいはシェルから呼び出されたPythonプロセスは、すべてジョブとして扱われる、ということになります。
Performance Details / Host
Performance Overviewから指定のHostを選択すると、このダッシュボードを表示できます。 ホストごとの性能メトリクスを一覧できるため、特定のノードでのリソース使用状況やボトルネックを分析することができます。

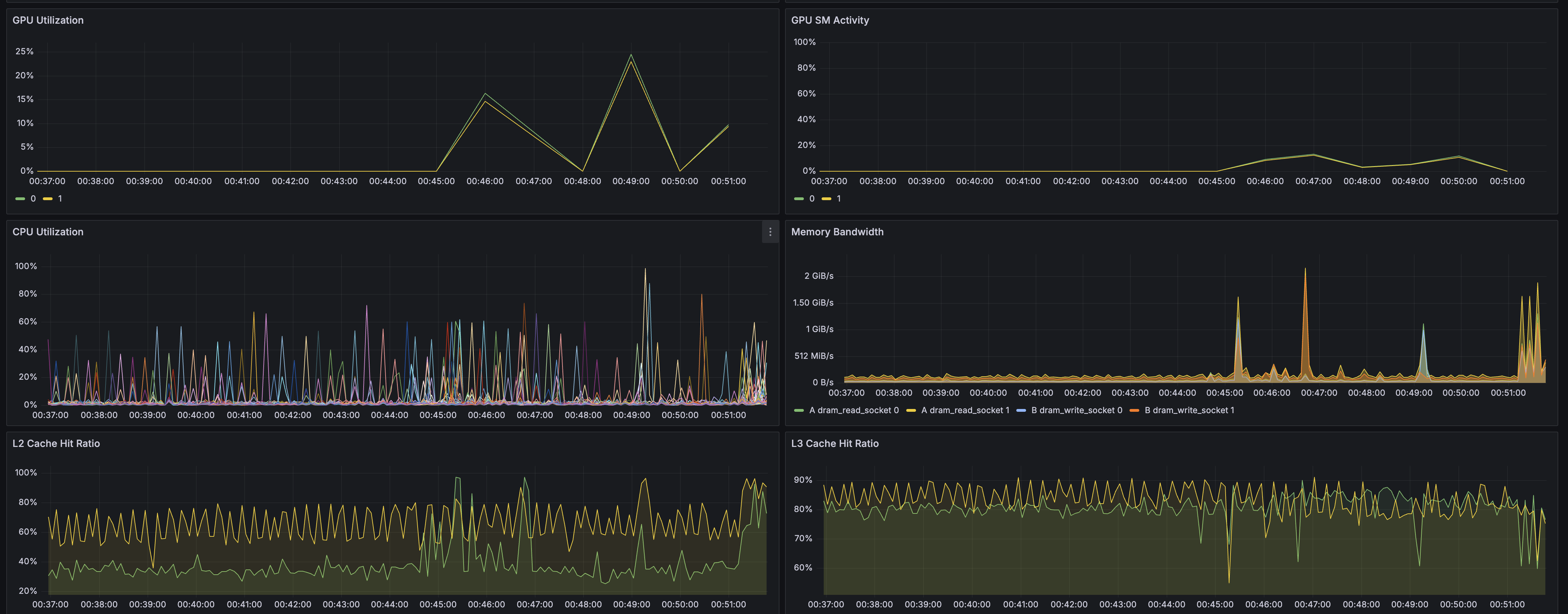
続くパネルでは、以下のメトリクスを時系列グラフとして表示しています。
- GPU Utilization
- GPU SM Activity
- CPU Utilization
- Memory Bandwidth
- L2 Cache Hit Ratio
- L3 Cache Hit Ratio
- Network Bandwidth
- Storage Bandwidth
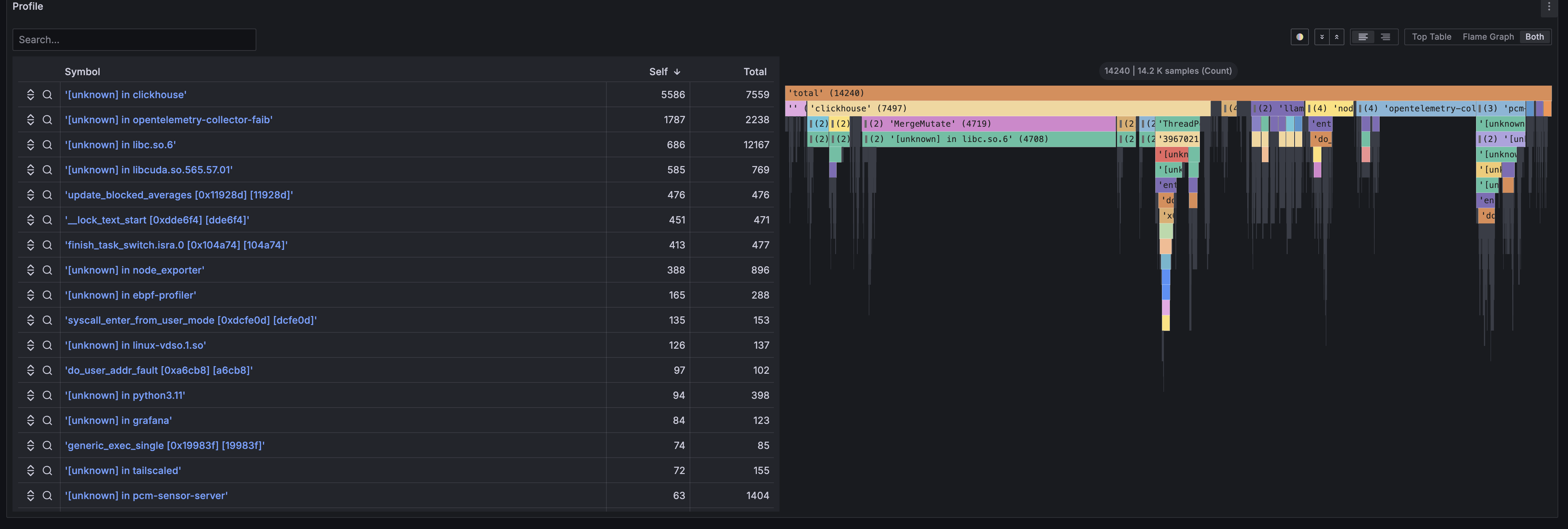
また、Profileパネルでは、ノード上で動作しているプログラムのフレームグラフを見ることができます。 フレームグラフは、サンプリングされたスタックトレース情報を再構築することで、プログラムのボトルネックをソースコードレベルで解析するためのパネルです。 フレームグラフの詳細については解説ページを参照してください。
以下のPrometheusエクスポーターがサポートされており、これらのメトリクス情報によってシステム全体のパフォーマンスボトルネックを特定し、最適化のポイントを見つけることができます。
これらのエクスポーターが収集するメトリクスを組み合わせることで、CPU、GPU、メモリ、ネットワーク、ストレージなど、システム全体のリソース使用状況を包括的に監視・分析できます。詳細については、リンク先の公式ドキュメントを参照してください。
標準ダッシュボード以外にも、これらのエクスポーターが提供するメトリクスを使用してカスタムパネルを追加できます。詳細な手順とクエリ例については、カスタムパネルの追加方法を参照してください。
Performance Details / Job
Performance Overviewから指定のJobを選択すると、このダッシュボードを表示できます。 ジョブごとの性能情報が確認でき、各種メトリクスはジョブの実行時間およびホストに予めフォーカスされているため、特定ジョブでのリソース使用状況やパフォーマンスのボトルネックを分析できます。
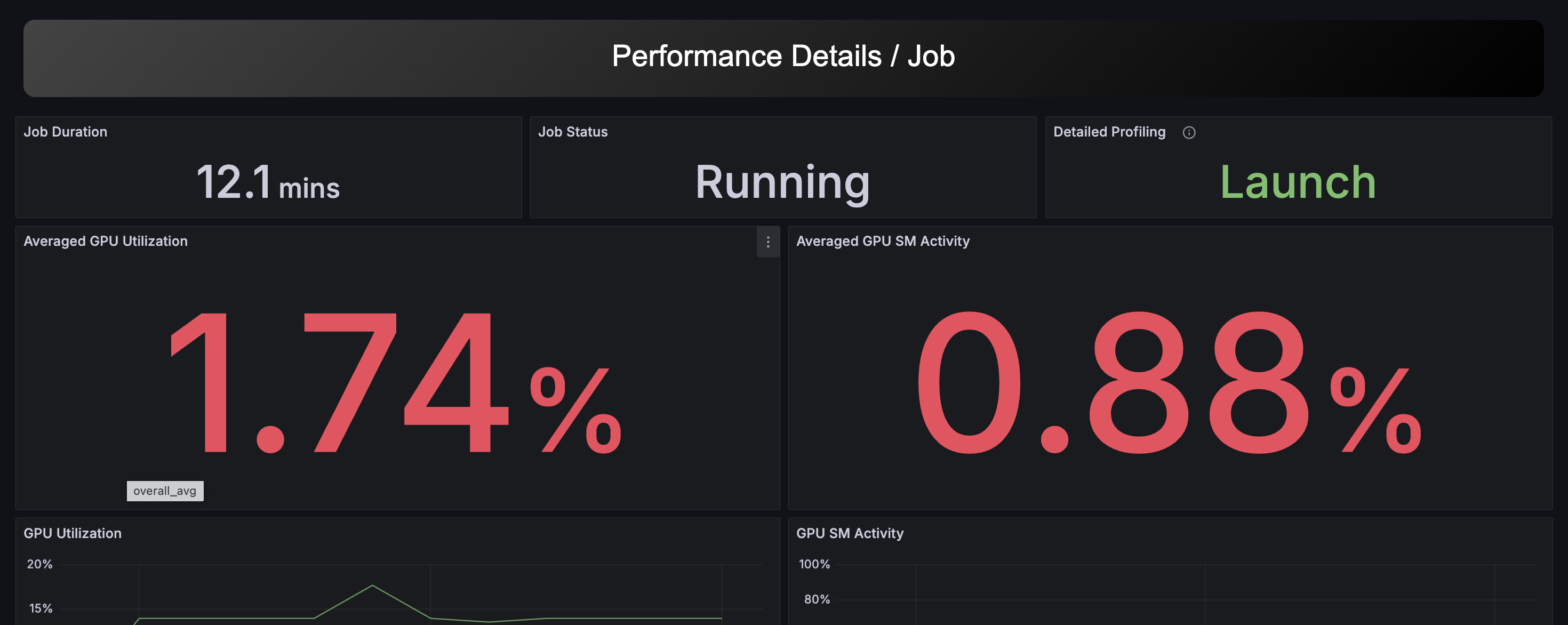
実行中のジョブのうち、特定の条件に当てはまるものについては、Launch というパネルから後述の詳細プロファイリング機能を使用することができます。
プロファイリング機能の詳細については、次のセクションを参照してください。
Performance Details / Profiling [Beta]
特定のプロセス、特にPyTorchプログラムに関するGPUの詳細なプロファイル情報を取得したい場合にこの機能を使用します。 この機能によって、実行中のプログラムに対して外部から瞬間的にPyTorch Profilerと同等の情報を取得することができます。 詳細プロファイルによる性能劣化を避けたい場合は、必要な区間のみプロファイルを取得するようにして下さい。
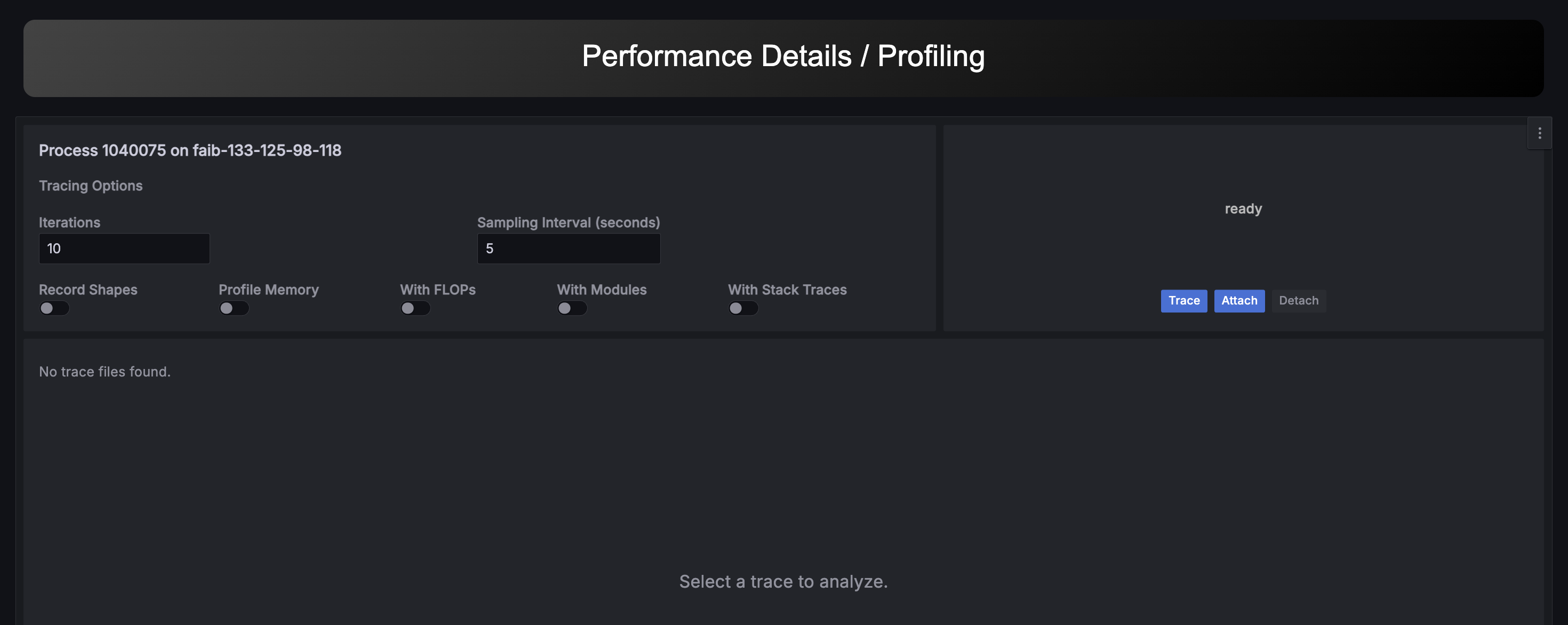
本機能を有効にするには、適切なスコープで以下の環境変数を有効にする必要があります。
export KINETO_USE_DAEMON=1
export KINETO_DAEMON_INIT_DELAY_S=3
export KINETO_IPC_SOCKET_DIR="/tmp/.dynolog_socket"
この環境変数を設定することによる、実行時間に対する固定オーバヘッドは以下のとおりです。
- Torchライブラリを使用しないプログラム: ゼロ
- Torchライブラリを使用するプログラム: KINETO_DAEMON_INIT_DELAY_S に指定した秒数
また、詳細プロファイル機能から情報を取得(Attach or Trace)している間は、その区間中のみ数%から最大50%程度の追加オーバーヘッドが発生します。
トレースには2つのモードがあります:
- Simple Trace: Trace ボタンをクリックすると、選択した回数だけプログラムのトレースが行われます。
- Continuous Profiling: こちらも Attach ボタンをクリックして開始しますが、指定した
time_duration(秒単位)ごとに繰り返しプロファイリングを行います。
プロファイリングを停止したい場合は、Detach ボタンを使います。
Trace、あるいはAttachによってプロファイルを取得すると、下のパネル上にキャプチャされたプロファイル情報が表示されます。
- View をクリックすると、詳細なプロファイル情報を別ウィンドウで表示します。
- Analyze をクリックすると、プロファイルの要約情報が確認できます。

本機能で取得するデータのサイズは大きくなるため、情報の表示には、時間がかかる場合があります。