Analyze Performance
Performance Overview
This dashboard allows you to view performance-related information for all GPU hosts being observed.
At the top of the page, statistical values of important GPU metrics for the target period are displayed. The closer these values are to 100%, the more frequently the GPU is being used.
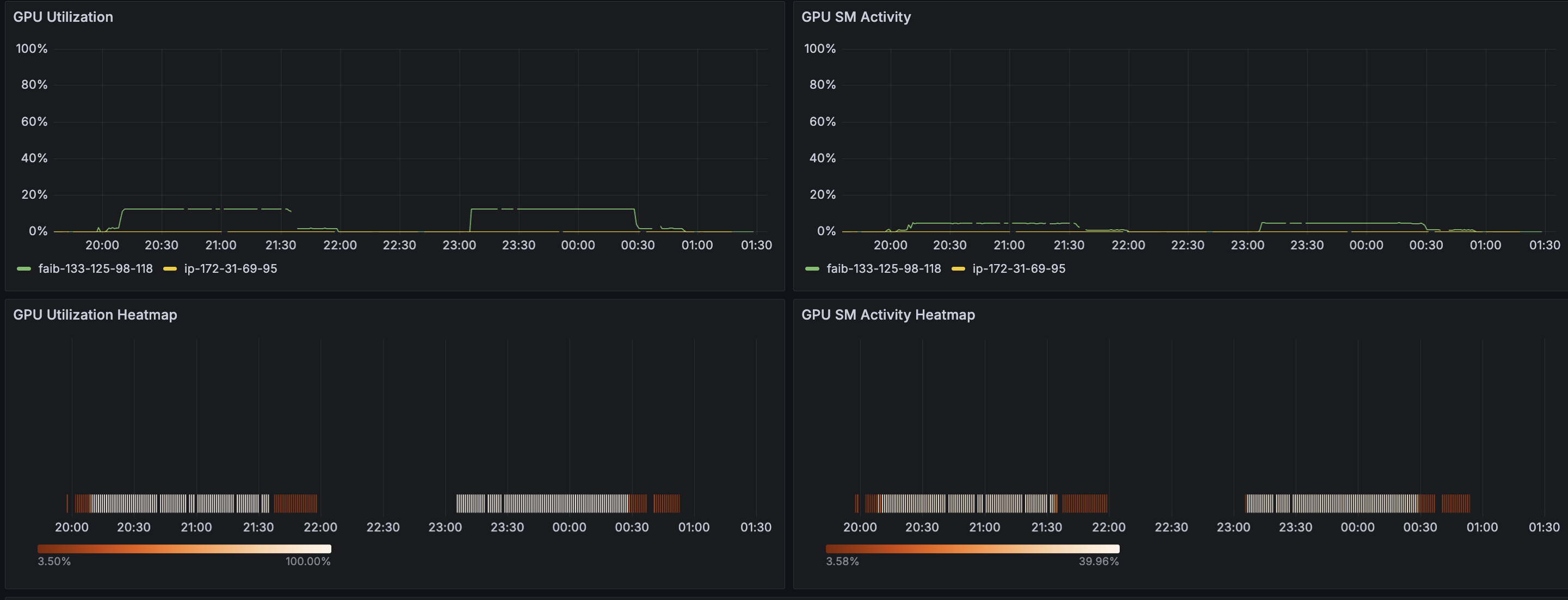
Below that, time-series transitions of these metrics per host and heatmaps per GPU are displayed together.
At the bottom of the dashboard, host and job information is displayed in table format. Each row is a hyperlink, and clicking these links navigates to the Performance Details dashboard for the corresponding host or job.
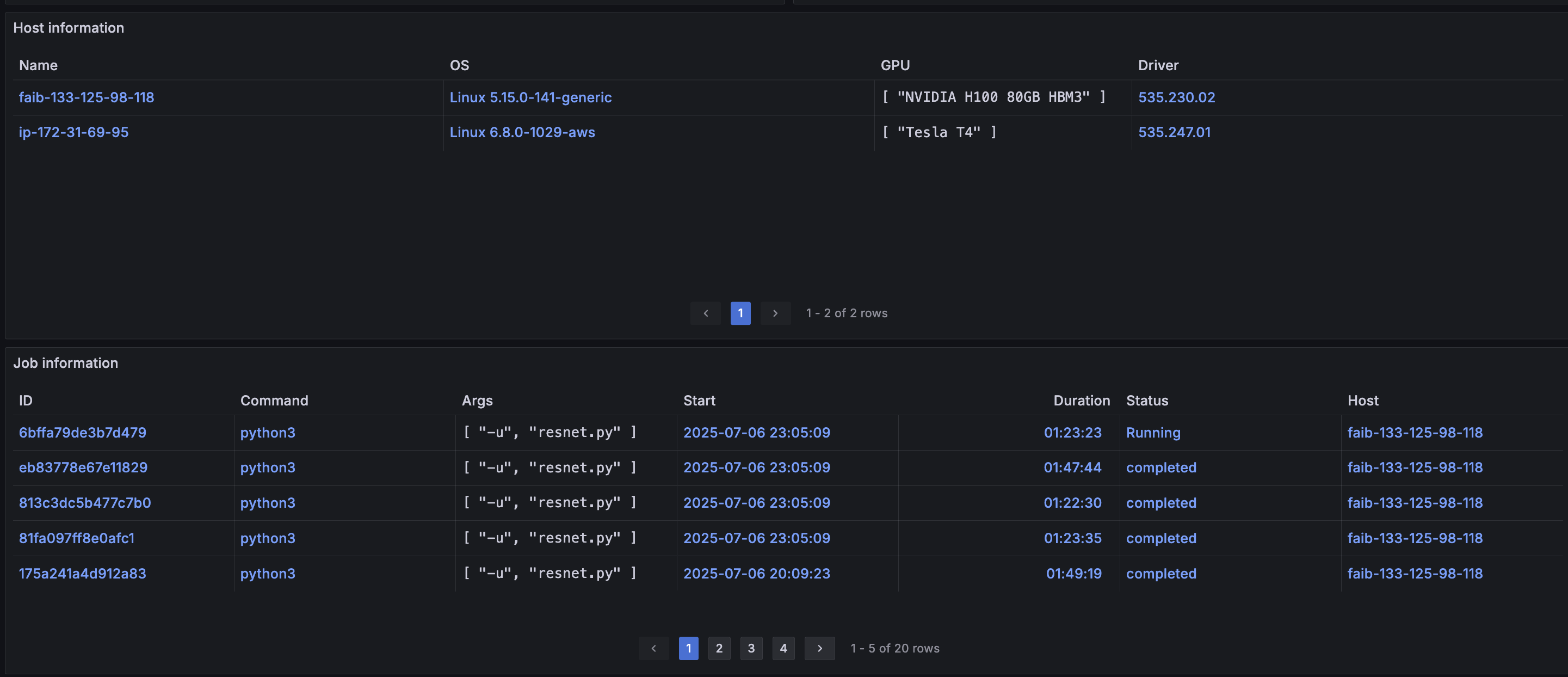
A host refers to each compute node that AIBooster is observing.
A job refers to processes whose process tree ID (meta-information about processes) meets specific conditions.
The process tree ID is created by listing all parent processes' /proc/<pid>/comm in chronological order, separated by /.
By default, process tree IDs matching the following regular expression are treated as jobs:
systemd.*/([a-z]*sh|containerd-shim-runc-v2)/.*python[0-9.]*$
Interpreting this expression means that all Python processes called from within containers or from shells are treated as jobs.
Performance Details / Host
This dashboard can be displayed by selecting a specific Host from Performance Overview. Since you can view performance metrics per host, you can analyze resource usage and bottlenecks on specific nodes.

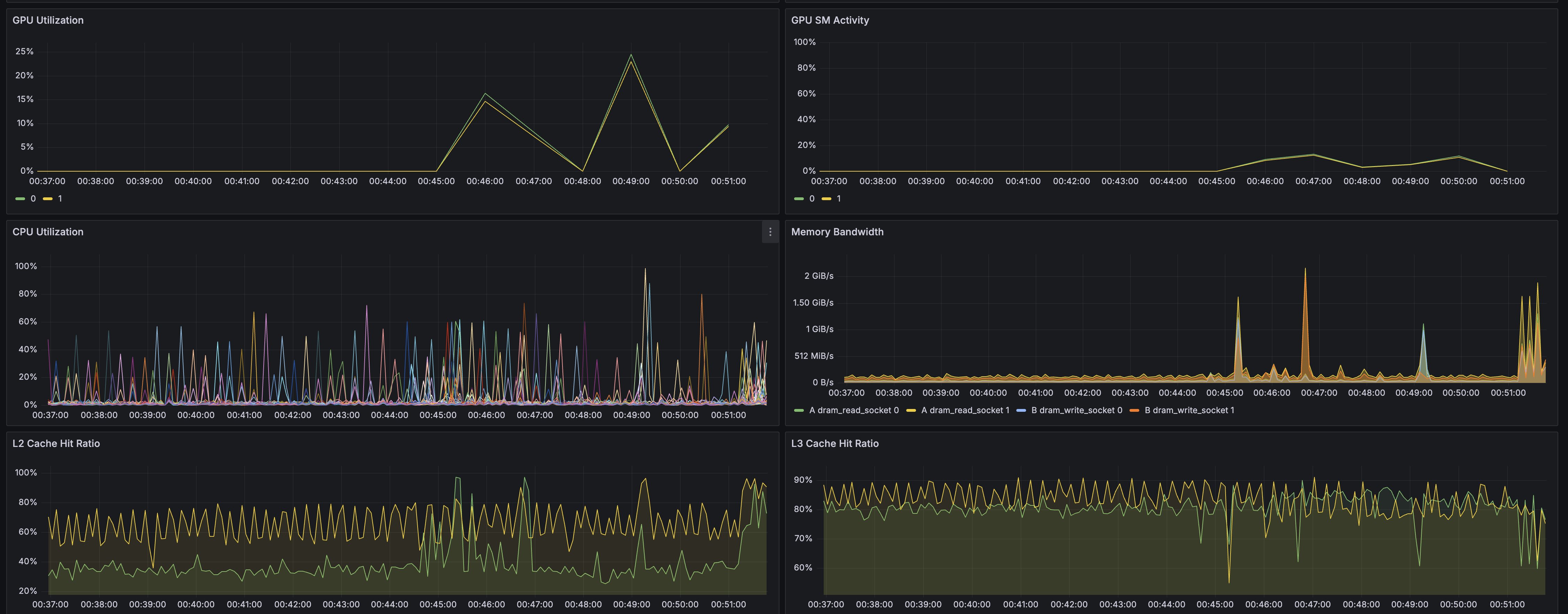
The following panels display these metrics as time-series graphs:
- GPU Utilization
- GPU SM Activity
- CPU Utilization
- Memory Bandwidth
- L2 Cache Hit Ratio
- L3 Cache Hit Ratio
- Network Bandwidth
- Storage Bandwidth
Additionally, in the Profile panel, you can view flame graphs of programs running on the node. Flame graphs are panels for analyzing program bottlenecks at the source code level by reconstructing sampled stack trace information. For details about flame graphs, please refer to the explanation page.
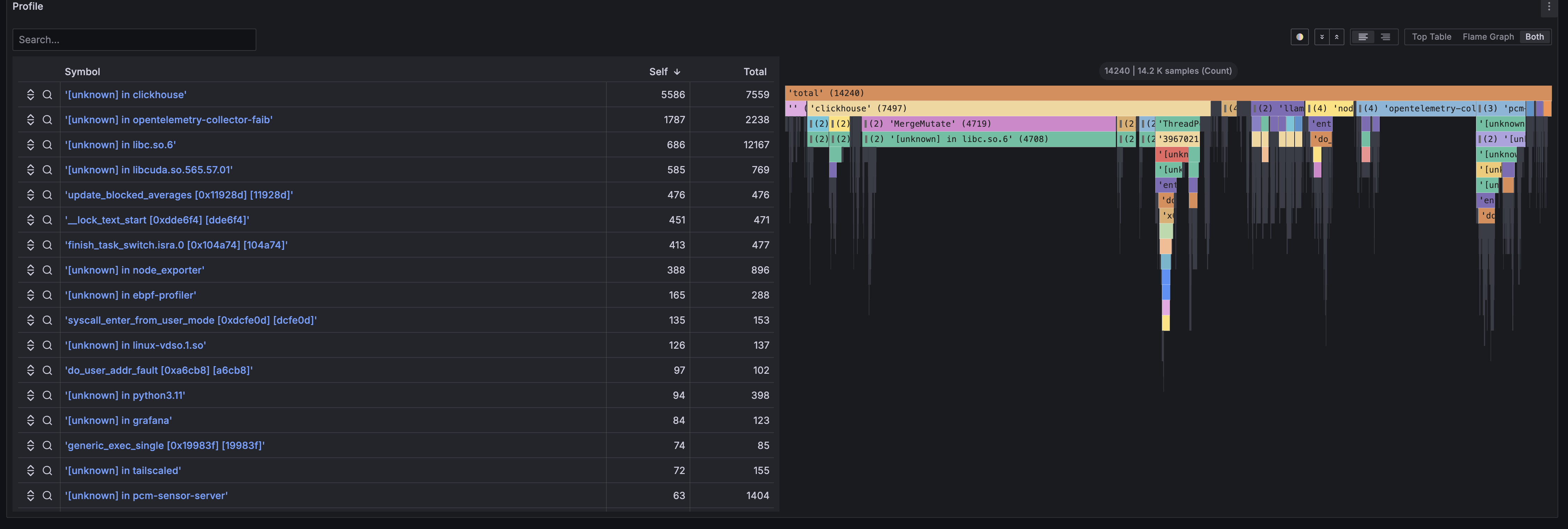
The following Prometheus exporters are supported, and their metric information can help identify system-wide performance bottlenecks and find optimization points:
By combining the metrics collected by these exporters, you can comprehensively monitor and analyze resource usage across the entire system, including CPU, GPU, memory, network, and storage. For details, please refer to the official documentation at the linked pages.
You can add panels using metrics provided by these exporters. For detailed procedures, please refer to Adding Custom Panels Using Panel Library.
Performance Details / Job
This dashboard can be displayed by selecting a specific Job from Performance Overview. You can check performance information per job, and since various metrics are pre-focused on job execution time and host, you can analyze resource usage and performance bottlenecks for specific jobs.
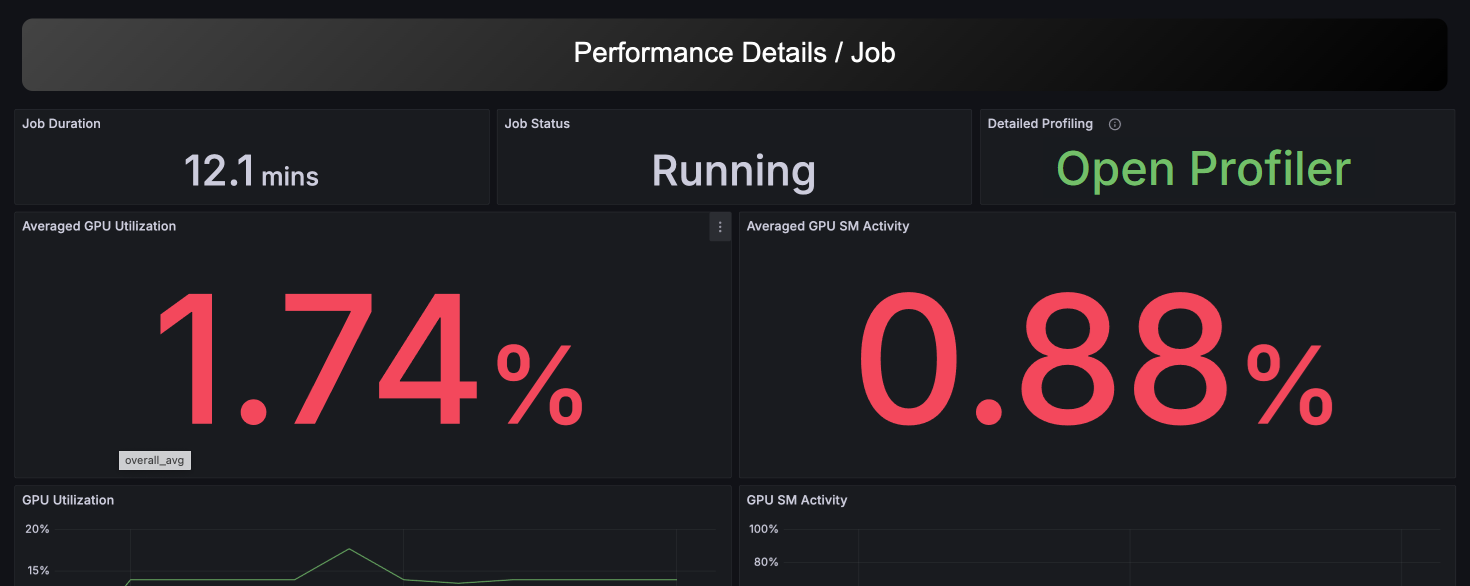
For running jobs that meet certain conditions, an Open Profiler option will be displayed. By clicking it, you can access the detailed profiling feature described below. For details about the profiling feature, please refer to the next section.
Performance Details / Profiling [Beta]
Use this feature when you want to obtain detailed GPU profile information for specific processes, particularly PyTorch programs. This feature allows you to obtain information equivalent to PyTorch Profiler from outside the running program instantaneously. To avoid performance degradation from detailed profiling, please obtain profiles only for necessary intervals.
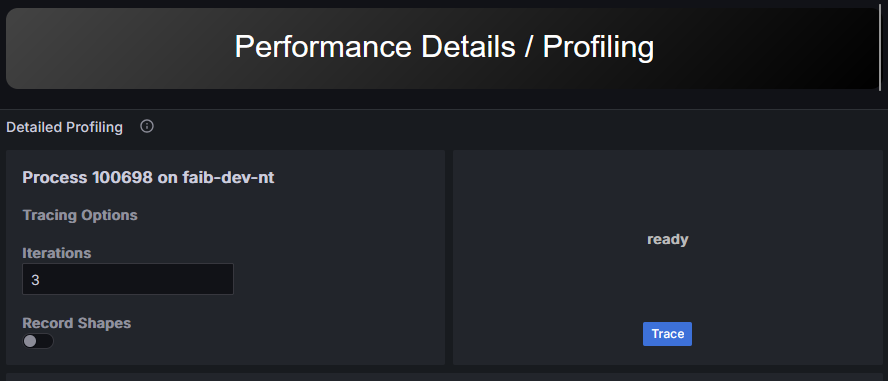
Operating Conditions
This feature depends on the functionality of the pytorch/kineto library used internally by PyTorch Profiler.
You can check if this feature is supported by running the following script in the execution environment of the PyTorch program you want to profile. If all results are True, you can use this feature.
$ python -c 'import torch; print(torch.cuda.is_available());print(torch.profiler.kineto_available());print(torch.__config__.show().find("-DUSE_KINETO")>0)'
True
True
True
Prerequisites
To enable this feature, you need to set the following environment variables in the appropriate scope:
export KINETO_USE_DAEMON=1
export KINETO_DAEMON_INIT_DELAY_S=3
export KINETO_IPC_SOCKET_DIR="/var/run/aibooster/dynolog_socket_dir"
Setting these environment variables will introduce overhead according to the number of seconds specified in KINETO_DAEMON_INIT_DELAY_S.
Additionally, while obtaining information from the detailed profiling feature, additional overhead of several percent to a maximum of about 50% occurs only during that interval.
Profile Execution
Click the Trace button to trace the program for the selected number of iterations.
When you obtain a profile through Trace, the captured profile information is displayed in the panel below.
- Click View to display detailed profile information in a separate window.
- Click Analyze to check profile summary information.

Since the data size obtained by this feature can be large, displaying information may take time.
If the profile cannot be obtained, please check the following:
- Verify that the Operating Conditions are met
- Verify that each environment variable in Prerequisites is properly set
echo ${KINETO_USE_DAEMON}(shell) oros.getenv("KINETO_USE_DAEMON")(Python)
Also, when environment variables are correctly loaded, the following output may be displayed during PyTorch program execution:
INFO:2025-09-16 03:58:15 109546:109546 init.cpp:140] Registering daemon config loader, cpuOnly = 0
INFO:2025-09-16 03:58:15 109546:109546 CuptiActivityProfiler.cpp:243] CUDA versions. CUPTI: 24; Runtime: 12060; Driver: 12090
INFO:2025-09-16 03:58:15 109546:109546 DaemonConfigLoader.cpp:66] Setting communication fabric enabled = 1
INFO:2025-09-16 03:58:15 109546:109546 IpcFabricConfigClient.cpp:88] Setting up IPC Fabric at endpoint: dynoconfigclientd8255d6f-2eed-4bde-a9c1-dd6baa485caf status = initialized
INFO:2025-09-16 03:58:15 109546:109546 DaemonConfigLoader.cpp:66] Setting communication fabric enabled = 1
INFO:2025-09-16 03:58:15 109546:109546 DaemonConfigLoader.cpp:28] Reading base config
WARNING:2025-09-16 03:58:15 109546:109546 IpcFabricConfigClient.cpp:146] Missing IPC Fabric implementation for getLibkinetoBaseConfig
The output will vary depending on the PyTorch version.