AIBoosterとは?
AIBoosterは、AIワークロードの性能を継続的に観測し改善するためのパフォーマンスエンジニアリングプラットフォームです。
- PO: Performance Observability
- 🔍 可視化: 各種ハードウェアの使用率、効率などを一覧
- 📊 分析: ソフトウェアボトルネックを特定し、改善点を発見
- PI: Performance Intelligence
- ⚡ 性能向上: 自動チューニングで性能継続的に向上
- 💰 コスト削減: 非効率なリソース利用を削減しROIを改善
ユーザーは、可視化ダッシュボードを通じてCPU、GPU、インターコネクト、ストレージといった各種ハードウェアリソースの利用効率やソフトウェアのボトルネックを可視化し、AIワークロードの性能特性を分析することができま�す。 さらに、AIワークロード用にデザインされた最適化フレームワークを適用することで、効率的な性能改善が可能になります。
AIBoosterを活用して、高速かつ低コストなAIの学習や推論を始めましょう!
機能ハイライト
ユーザ環境に合わせた性能観測機能のカスタマイズ
AIBoosterの性能観測機能は、クラスタ上で実行されるAIワークロードを定点観測することで、以下のような複数の体験をユーザーに提供します。
- クラスタ全体、中長期感といったマクロな性能トレンドの把握
- ノードやデバイスごとのハードウェア利用効率の監視
- ワークロードごとの性能特性の違いを分析
本リリースでは、ユーザーの要件に合わせてより柔軟な性能観測の体験を実現するため、以下のパラメータを簡単に変更できるようになりました。
- メトリクスの収集間隔
- トレースに付与されるユーザー定義タグ
これらのカスタム機能は、ユーザーに以下のような利点をもたらします。
-
観��測の粒度を調整することで観測による負荷を最小化
例えば、中長期でのトレンドを重点的に観測したい場合にはミリ秒レベルでのメトリクス収集は過剰であり、メトリクスの収得間隔を柔軟に変更することで、必要なリソースを低減することができます。 これにより、観測のオーバーヘッドを抑えたまま多用な環境への導入が可能になりました。
詳細については メトリクス収集間隔を変更する を参照してください。
-
ユーザー独自の観点でのワークロードの性能分析を可能に
ユーザー定義タグを活用することで、収集したワークロードをユーザー独自の観点で分類することができます。 これらの分類に基づいて集計を行うことで、モデルの種類、実行時の設定、対象のデータセットなど、より深い観点での性能分析が可能になります。

ユーザー定義タグは Performance Details / Job 画面で変更できます。
AcuiRT モデル変換の診断レポート
AcuiRTは推論向けのAIモデル変換を支援するフレームワークです。深層学習コンパイラによるモデル変換を適用することによって、ターゲットデバイス上での推論処理の高速化を実現しています。
しかしながら、ある程度の規模を備えた実用的なモデルにおいては、以下のような理由によって、モデルの変換を一度で成功させることが難しい場合が多く存在します。
- 入力モデルが静的なグラフに変換できない
- 深層学習コンパイラやターゲットハードウェアが一部のオペレータに対応していない
これらの問題を回避するために、従来ではコンパイル設定やAIモデルの改良などの人力による介入が欠かせませんでした。
本リリースでは、モデル変換結果の詳細な診断ができる機能を大幅に強化しました。エンジニアは変換結果をCLI出力またはレポートファイルで確認することで、ターゲットデバイスへのデプロイ時に発生する問題を特定し、リファクタリングによって解決する、という開発サイクルを高速に回すことができます。
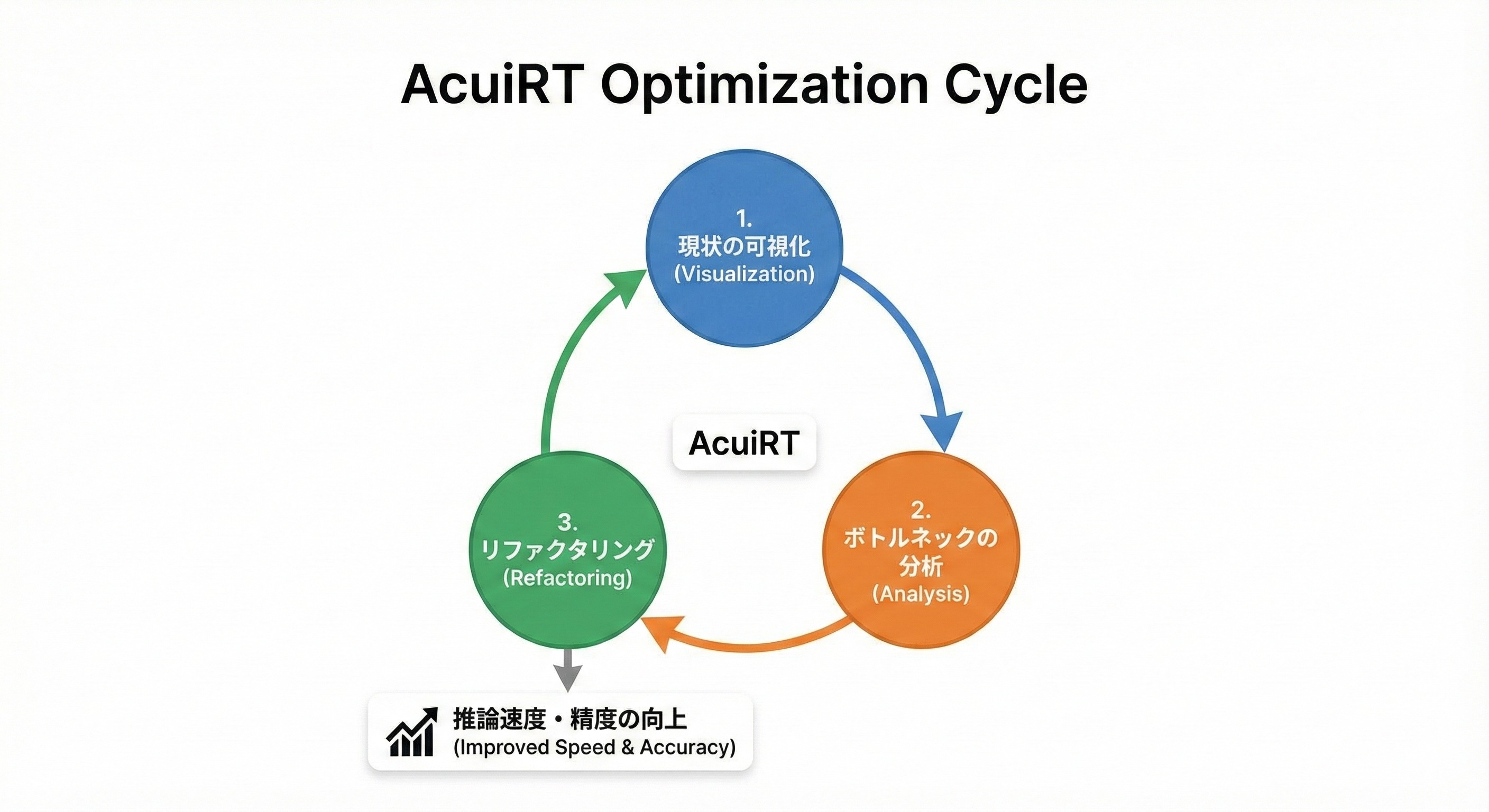
本リリースに含まれる機能の詳細は下記です。
変換結果の可視化
モデル変換の成功・失敗状況を詳細に把握できます。
- レイヤー単位の変換成功率: モデル全体のうち、どの程度のレイヤーが正常に変換されたかを確認できます。
- レイヤーごとの変換結果: 全レイヤーに対する変換成功または失敗のステータスを一覧で確認できます。失敗したレイヤーについては、エラーメッセージも併せて出力されます。
パフォーマンスプロファイリング
変換後のモデルの性能特性を詳細に分析できます。
- 推論速度(Latency): 変換後のモデルの推論処理時間を測定できます。
- レイヤー単位の推論時間内訳: 各レイヤーの処理にかかる時間を個別に確認でき、ボトルネックの特定に役立ちます。
認識精度
モデル変換時の精度劣化の問題を詳細に調査するための情報を取得できます。
- 認識精度(Accuracy): 変換後のモデルの推論精度を測定し、変換前のモデルからの精度劣化を確認できます。
適用事例
2次元物体検出モデルをNVIDIA社のGPU向けに変換した事例を紹介します。
このモデルをそのまま変換した場合、変換成功率は全レイヤー中わずか16%にとどまりました。また、モデルが部分的にしか変換されなかった影響で、推論速度も変換前より低下してしまいました。しかし、診断レポートで失敗したレイヤーとエラー内容を確認し、モデルのリファクタリングを行った結果、わずか4時間のリファクタリングで変換成功率100%を達成しました。さらに、変換後のモデルでは推論速度が約1.25倍に向上することが確認されました。
詳しい利用方法については、複雑なモデルでの変換結果の分析とリファクタリングを参照してください。
✨ 各種ガイド
クイックスタートガイド
AIBoosterの概要、セットアップ方法と簡単な使い方について学びましょう。
性能観測ガイド
AIワークロードの性能を観測するための可視化ダッシュボードの使い方について学びましょう。
性能改善ガイド
AIワークロードの性能を改善するためのフレームワークの使い方について学びましょう。